Theorem 0. The minimum guaranteed latency for the globally highly available strong consistency database is 133 ms.

1 Abstract
The article introduces step-by-step the formal vocabulary and auxiliary lemmas and theorems to prove the main theorem 0. Finally, as a consequence, the CAL theorem is formulated.
2 Introduction
Modern applications require intensive work with huge amount of data. It includes both massive transactional processing and analytical research. As an answer to the current demand, the new generation of databases appears: NewSQL databases. Those databases provide the following important characteristics: horizontal scalability, geo-availability, and strong consistency.
NewSQL era opens new possibilities to store and process so called Big Data. At the same time, the important question appears: "how fast the databases might be?". It is very challenging task to improve the performance and latency parameters because it involves almost all layers while building the databases: from hardware questions about data centers connectivity and availability to software sophisticated algorithms and architectural design.
Thus, we need to understand the degree of latency optimizations and corresponding limitations that we have to deal with. The article tries to find answers to that challenge.
3 Model
The globally distributed databases have different characteristics and assumptions based on the features and scalability properties they provide. I consider the following assumptions to specify the model to be used.
First of all, I consider that all participants belong to the sphere with some radius
The participants involved in the process are cooperated through the message exchanging. Each participant
3.1 Speed
Definition 3.1.1. The distance between two participants is the length of the curve between two points on the sphere.
Definition 3.1.2. The minimum distance between two participants is the minimum distance across all possible curves on the sphere that may connect two participants.
The message exchanging does not take place immediately and has time characteristics.
Definition 3.1.3. The information propagation speed between two participants
The information has the limited propagation speed.
Definition 3.1.4. The speed of information propagation has the limit
Thus the minimum time required to propagate the information from participant
Definition 3.1.5. The wave propagation between participants
Thus the wave propagation is spread on the sphere with speed
Lemma 3.1.1. Information cannot propagate faster than wave propagation.
Proof. By definition of the wave propagation: it uses the largest speed
3.2 Consistency
Strong consistent databases have a different meaning in different contexts. I consider linearizability property as strong consistency.
Definition 3.2.1. The operation is the message issued by the client to be committed.
The proof is based on the following linearizability characteristics:
- There is a global sequence of operations. Each operation is committed using some incremental index
. - To commit the operation on the
index the system must have the information about the whole previous history, e.g. must know the information about all previous commits with indexes . - The system may respond to the client with successful operation commit only if it commits the operation into the global sequence of operations.
- If the system commits the operation using index
thus any participant that knows about committed operation for index has the same operation for that index. Thus each participant has the same information about prefix of the global sequence of operations.
Theorem 3.2.1. If there are two committed linearizable operations issued by the clients thus there is a participant that knew the information related to the both operations.
Proof. To commit linearizable operations the participant must know the history for the previous operations. Thus, in any case, it knows the current operation and previous one, thus it knows both.
The theorem can be easily generalized for any number of committed operations.
Theorem 3.2.2. If there are several committed linearizable operations issued by the clients thus there is a participant that knew the information related to all operations.
Proof. The same as theorem 3.2.1.
Theorem 3.2.3. If there are several committed linearizable operations issued by the clients thus there is a point on the sphere where all waves propagate from all clients to that point.
Proof by contradiction. If there is no such point thus there is no any participant that has all information related to operations due to lemma 3.1.1. It contradicts to theorem 3.2.2.
Definition 3.2.2. The client commits the operation when it receives the message from a participant that has committed the operation.
Definition 3.2.3. The client commit latency is the time between issuing the operation and committing it by the client.
Definition 3.2.4. The guaranteed commit latency is
Definition 3.2.5. The wave half-time is the time needed to propagate from the participant to the diametrically opposite participant.
Definition 3.2.6. The wave full-time is doubled wave half-time.
Theorem 3.2.4. The minimum guaranteed commit latency is the wave half-time.
Proof. Let all clients be spread across the sphere. Let all clients issue the operation to be committed at the same time i.e. concurrently. To commit the sequence of operations according to theorem 3.2.3 there must be at least one point on the sphere where all waves propagate from all clients to that point
Theorem 3.2.5. The wave half-time guaranteed commit latency is theoretically achievable.
Proof by example. Let all participants be spread across the sphere. In that case, any client issues the operation to the closest participant. Each participant broadcasts the operation to others and waits for the response from all participants, then commits the sequence of received operations. The commit latency is described as the largest wave propagation time between participants and equals to the wave half-time.
3.3 Geo Split
The links are unreliable. Thus at any time there is a possibility when part of the system becomes unavailable for the rest of the system. It strictly affects the algorithms to handle such complex scenarios.
Definition 3.3.1. Group of participants is unavailable when the rest of participants cannot propagate the information to that group.
Definition 3.3.2. Split is the situation when there is an unavailable group.
Definition 3.3.3. The system is highly available when it can handle split.
Theorem 3.3.1. The guaranteed commit of the highly available system requires at least one round trip between available participants.
Proof by contradiction. Let us assume that half round trip is enough to commit. Consider the participant
The theorem provides the important clue about the latency. The totally available system requires only half round trip to commit the operations while the highly available system requires at least one round trip.
Definition 3.3.4. The commit group is the participants that make a decision to commit the operations.
Theorem 3.3.2. The minimum guaranteed commit latency for the highly available system is the wave full-time.
Proof. Let all clients be spread across the sphere. Let all clients issue the operation to be committed concurrently. Let
For leader-based consensus, the theorem becomes trivial because we can put the client on the opposite side of the leader and all operations must be propagated through the leader.
Theorem 3.3.3. For the highly available system, the wave full-time guaranteed commit latency is theoretically achievable.
Proof by example. Put three participants around any point on the sphere on equidistant positions with the distance
Now we can prove the main theorem 0.
Proof of theorem 0. The wave full-time of the Earth according to definitions 3.2.5 and 3.2.6 is equal to
4 Medium and Effectiveness
I have introduced the term theoretically achievable meaning the following:
- Latency is described only the wave propagation and does not have any packet loss or delay during transmissions/handling/routing etc.
- There is unlimited bandwidth for the links.
- Each client is connected with the participant.
The reality has another understanding related to the specified items. The common case is that information propagates slower than wave propagation. If we use the ratio
The idea and intuition are very simple: the more transparent medium
5 Optimization
Definition 5.1. Operation commit period is the time period between the time point of operation being issued and client commit point of time.
Definition 5.2. Two or more operations are not concurrent if their operation commit periods are not intersected.
Definition 5.3. Nonconcurrent period is the runtime situation when there are no concurrent operations.
It is important to emphasize that nonconcurrent period is the runtime situation based on the client's behavior and not a priory knowledge.
Definition 5.4. Nonconcurrent commit latency is the commit latency during the nonconcurrent period.
Theorem 5.1. The minimum guaranteed nonconcurrent commit latency is the wave half-time.
Proof by contradiction. Let two diametrically opposite clients issue the operations simultaneously. To detect concurrent execution there must be a participant
Theorem 5.2. The guaranteed nonconcurrent commit latency more than the wave half-time is theoretically achievable.
Proof by example. Let all participants be placed equidistantly on the equator. If a number of participants are
6 Solar System
Here is a table that represents the minimum guaranteed latencies for the solar system objects in the universe:
| Planet System | Latency |
|---|---|
| Earth | 133 ms |
| Moon | 36 ms |
| Mercury | 51 ms |
| Mars | 71 ms |
| Venus | 126 ms |
| Jupiter | 1.4 s |
| Sun | 14 s |
| Earth-Moon | 2.6 s |
| Earth-Mars | 6-44 min* |
*Depending on the position of the planets.
7 Connection Relaxing
Theorem 3.3.2 assumes that the participants are connected with each other using surface links thus the wave propagates on the sphere. Let us relax this requirement and allow the wave propagates directly through the surface. One of the possibility how to achieve this is to use neutrino particles [3] (BTW, do you know, that neutrino is detected by using Cherenkov radiation [2] due to extremely low interaction with the matter).
Definition 7.1. Straight connection is the shortest geometrical connection in space.
Using the mentioned shortcut we may obtain the following theorem.
Theorem 7.1. The minimum guaranteed latency for the globally highly available strong consistency database using straight connections is 85 ms.
Proof. The wave full-time of Earth for the straight connections is
8 Place Relaxing
Theorem 7.1 assumes that all participants are placed on the sphere. In addition to connection relaxing let us assume that the database participants may be placed at any point within the sphere.
Definition 8.1. The arbitrarily placed database is the database where participants can be placed at any point within sphere using straight connections.
Theorem 8.1. The minimum guaranteed latency for the globally available strong consistency arbitrarily placed database is 42 ms.
Proof. Let all clients are spread across the sphere and they issue the operation to be committed at the same time. To commit the sequence of operations according to theorem 3.2.3 there must be at least one point on the sphere where all waves propagate from all clients to that point. Let us choose the earliest moment of the time where that point
Theorem 8.2. The minimum guaranteed latency 42 ms for the globally available strong consistency arbitrarily placed database is theoretically achievable.
Proof by example. Let
9 Reliability and Fault-Tolerance
Theorem 3.3.2 is proved under assumptions that any participant lives forever and handles the incoming messages correctly. If we introduce additional failure modes (fail-stop, fail-silent etc) it is evident that latencies cannot become less than theorems 3.3.2, 7.1 and 8.1 state because the system must resend the information to redundant participants increasing availability and timings as well.
Nevertheless, it could be easily proved that latencies are achievable at the same values even in the case of arbitrary node failures.
Definition 9.1. Byzantine participant group is the group of nodes that uses Byzantine consensus to handle received and send information under arbitrary failure.
Definition 9.2. Live Byzantine participant group is the Byzantine participant group that achieve consensus under a limited fixed number of round trips between participants within the group.
Theorem 9.1. Live Byzantine participant group behaves as a single participant without failure.
Proof. If Byzantine consensus makes the progress due to liveness conditions it means that it operates normally even in the case of arbitrary failures because consensus algorithm preserves safety.
Definition 9.3. The link has efficiency
Note that
Definition 9.4. Group efficiency is
Definition 9.5. The group is flexible when group efficiency preserved under proportional distance changing between nodes.
Theorem 9.2. The commit latency of flexible live Byzantine participant group can be arbitrarily small.
Proof.
Based on theorem 9.2 we conclude that latencies are achievable because we could use live flexible groups to handle arbitrary failures that introduce negligible overhead on the overall latency timings.
Thus the theorem allows to easily build a fault-tolerant solution based on the simple non-fail model without sacrificing the timings of the database system.
10 Geo-Locality
Flexible groups and their commit latency allow introducing the notion of geo-locality. The idea is the following. Sometimes we know that the client at any time can be only in one place or near some place geographically. Thus we could choose the closest data center to handle client requests. The locality allows us to reduce the commit latency.
The only question is what to do if the client moves to another distant region. To preserve consistency we must apply group membership change protocol and move corresponding commit group to another closest data center preserving the minimum response timings. It may work if we implement a rather complex algorithm to change the group and put data centers around the world to be as close as possible to the client. But it does not work if there are concurrent clients across the planet at any time and space.
11 Consistency Relaxing
Another way to decrease the latency of operations is to relax the consistent requirements. E.g. one may consider applying sequential consistency still preserving geo-availability of the data.
The idea of sequential consistency can be represented by the following model. The client may issue any operation at any time. But instead of execution, the participant puts the operation into the queue to execute it later. The queue is the global across all participants. Another participant may dequeue the elements one by one and execute it serially. Thus, we serialize execution of all operations.
To reduce the write latency we could do the following approach. Instead of using the global queue to schedule operation the client chooses the closest consensus group inside some data center and put the operation into that queue. Periodically the operation is dequeued from that group and enqueued into the global queue transactionally using exactly once semantics.
The same approach can be used to reduce read latency by having the closest replicated data based. The replicated data is obtained by reading the operations from the global queue.
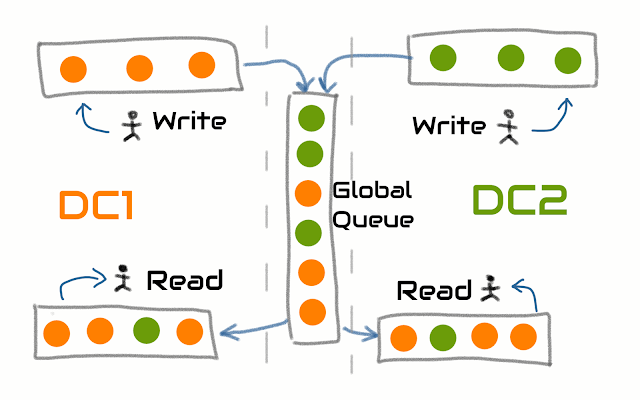
The approach allows to significantly reduce the latency of write operations by reducing the consistency level. At the same time, the actual latency to commit or execute the operation still cannot be less than mentioned theorems.
This scheme illustrates the idea of how to reduce latency without sacrificing geo-availability. The cost is the reduction of consistency guarantees.
12 CAL Theorem
CAL definition. CAL abbreviation means:
- "C" is the consistency that implies linearizability, e.g. strict consistency (linearizability+serializability) or linearizability.
- "A" is geo-availability meaning that client can be placed at any point on Earth surface.
- "L" is the guaranteed low latency, lower than related theorems states, e.g. submillisecond latency.
CAL theorem. It is impossible for a distributed database to simultaneously provide more than two out of the CAL guarantees.
Proof. See theorem 0 and considerations related to consistency relaxing and geo-locality.
Conclusion
I am very sad to present the theorem because it disallows building the best database with smartest geo-replicated consistent algorithms. It happened unintentionally, sorry for that.
On the other hand, it allows me to save my energy not to invent unworkable algorithms and relax by accepting the inevitability.
Nevertheless, the developed approach turned out to be powerful and productive. The wave propagation model allows understanding the minimum achievable latency in ideal situations even without knowing the connection topology and algorithms that are used to achieve consistency. Thus it is applicable always regardless of the system.
As the consequence, it provides the boundary to search and investigate the possible optimizations. One of the important application is to improve consensus algorithms by reducing latency based on the wave and information propagation consideration. In that perspective, the nonconcurrent optimization gives the key understanding how to further improve the consensus algorithm characteristics based on runtime situation.
At the same time, the article introduces the locality approach to significantly improve the latency. Limiting the distance between all participants including clients gives the possibility to further improve system characteristics without sacrificing the other parameters like consistency. The only requirement is to ensure that client cannot be at any point on geosphere simultaneously.
The theorem states the timings regarding ideal system meaning that there is no information (network packets) drops, node failure and other mechanisms that may potentially increase the overall latency. To deal with that complexity the article introduces the notion of efficiency and defines the way to obtain the direct value of the efficiency. The total latency can be easily recalculated based on the ideal latencies and efficiency. The medium model is thoughtful while considering the nonideality of the environment.
Moreover, the article provides the way how to shift consideration from totally available nodes to partially available nodes including arbitrary failures. The further application the Byzantine consensus allows creating a robust infrastructure and treating each participant as totally available. Of course, the model can be easily reduced to the normal consensus if the arbitrary failures are forbidden. The locality consideration to reduce the latency is applicable for the consensus groups as well.
The newly introduced CAL theorem allows tuning important entities describing the tradeoffs and connectivity between them. The possible way to preserve geo-availability and low latency is to use more relaxed consistency models e.g. briefly described sequential consistency application.
Now the turn from the wave propagation model to concrete consensus and transaction algorithms to make the closest bridge between them in the context of achieving the described guaranteed minimum latency. Those algorithms are coming.
Self-Examination Question. What is the minimum possible number of round trips required to commit the client operation excluding round trip from the client to the participants?
The answer is:
.
References
[1] Wikipedia: Refractive index
[2] Wikipedia: Cherenkov radiation
[3] Wikipedia: Neutrino
No comments :
Post a Comment