Summary
- Martin Kleppmann's fatal mistake.
- Physicochemical kinetics does mathematics.
- The half-life of the cluster.
- We solve nonlinear differential equations without solving them.
- Nodes as a catalyst.
- The predictive power of graphs.
- 100 million years.
- Synergy.
In the previous article, we discussed in detail Brewer's article and Brewer's theorem. This time we will analyze the post of Martin Kleppmann "The probability of data loss in large clusters".
In the mentioned post, the author attempts to simulate the following task. To ensure the preservation of data, the data replication method is usually used. In this case, in fact, it does not matter whether erasure is used or not. In the original post, the author sets the probability of dropping one node, and then raises the question: what is the probability of data loss when the number of nodes increases?
The answer is shown in this picture:

That is, the data loss grows proportional to the number of nodes.
Why does it matter? If we look at the size of the current clusters, we will see that their number has grown steadily over time. And so there's a reasonable question: Is it worth worrying about protecting your data and raising the replication factor? This has a direct impact on business, cost of ownership, and so on. Also, this example can be a great demonstration of how to produce a mathematically correct but incorrect result.
Cluster Modeling
It is useful to understand the model and simulation to demonstrate mistakes in calculations. If the model does not properly describe the actual behavior of the system, no matter what correct formulas are used, we can easily get the wrong result. And all because our model may not take into account any important parameters of the system that cannot be ignored. The science is to understand what's important and what is not.
To describe the life of the cluster, it is important to consider the dynamics of change and the relationship between different processes. This is the weak part of the original article because it has a static picture in it without any particular features associated with replication.
To describe the dynamics, I will use the methods of chemical kinetics, where I will use the ensemble of nodes instead of the particle ensemble. As far as I know, no one's used that formalism to describe the cluster behavior. So I'm going to improvise.
I introduce the following notation:
is the total number of cluster nodes. is the number of operable nodes. is the number of failed nodes.
Then it is obvious that:
The failed nodes include any problems: the disk got stuck, the processor, network, etc. broke down. I do not care about the reason, the very fact of the failure and inaccessibility of the data is important. In the future, of course, you can take into account more subtle dynamics.
Now let's write the kinetic equations of the processes of breaking and restoring cluster nodes:
These simplest equations mean the following. The first equation describes the process of node failure. It does not depend on any parameters and describes the isolated output of the node failure. Other nodes are not involved in this process. On the left, the original "composition" of the process participants is used, and the process products are on the right. Rate constants
Let us clarify the physical meaning of the rate constants. To do this, we write the kinetic equations:
From these equations we understand the meaning of constants
Or
That is, the quantity
Let's solve our kinetic equations. I want to make it right that I will cut corners wherever it is possible to get the simplest analytical dependencies that I will use for possible predictions and tuning.
Because my article reaches the maximum limit on the number of solutions of the differential equations, I will solve these equations using the steady state approximation:
Given that
If we assume that the recovery time
Chunks
Let
Where
The third equation should be clarified. It describes the second order process, not the first one:
If we did that, we'd have a curve of Kleppmann, which is not part of my plan. In fact, all nodes are involved in the recovery process, and the more nodes we have, the faster replication process goes. This is due to the fact that the chunks from the failed nodes are distributed approximately evenly across the cluster so that each node spends
It is also worth noting that the equation (3) on the left and right are placed the same "substance"
The steady state approach instantly provides the result:
or
Amazing result! That is, the number of chunks to be replicated is independent of the number of nodes! This is due to the fact that increasing the number of nodes increases the resulting process rate (3), thus compensating the increased number of
Let's estimate this value.
That is,
Replication Planning
In the previous calculation, we made an implicit assumption that nodes instantly know about the specific chunks to be replicated, and immediately begins the replication. In reality, this is completely wrong: metadata servers need to understand that node goes away, then to understand the specific chunks to be replicated and start the replication process on the nodes. This is not instantaneous and takes a while,
To take advantage of the lag, I will use the theory of a transition state or an activated complex, which describes the process of moving through a saddle point on a multidimensional surface of potential energy. In our view, we will have some additional intermediate status
Solving it, we find that:
Using the steady state approach, we find:
where:
As you can see, the result is the same as the previous one, except for the multiplier
. In this case, all of the previous statements are preserved: the number of chunks is not dependent on the number of nodes, which means that it does not grow with the growth of the cluster. . In this case, and grows linearly with the increase of the number of nodes.
To determine the case let's estimate
Thus, further expansion of the cluster beyond this number will increase the likelihood of loss of chunk under these circumstances.
What can be done to improve the situation? It would seem possible to improve the asymptotic behavior by shifting the boundary
Discussion of the Limit Cases
The proposed model actually splits clusters into two camps.
The first camp consists of relatively small clusters with the number of nodes < 1000. In this case, the probability of obtaining a under-replicated chunk is described by a simple formula:
To improve the situation, two approaches can be applied:
- Improve the hardware, thereby increasing
. - Speedup replication by reducing
.
These methods are generally clear enough.
In the second camp, we have large and extra-large clusters with a number of nodes > 1000. Here, the dependency will be defined as follows:
That is, it will be proportional to the number of nodes, which means that the subsequent increase in the cluster will have a negative impact on the likelihood of the appearance of under-replicated chunks. However, you can significantly reduce negative effects by using the following approaches:
- Continue to increase
. - Improve the detection of under-replicated chunks and subsequent replication scheduling, thereby reducing
.
The second approach is no longer obvious. It seems that there is no significant difference between 20 seconds and 100 seconds for the value
It's worth to consider
That is, it increases the number of available nodes. So, an improvement of
Comparison of Approaches
I would like to compare the two approaches. The following graphs will tell you this eloquently.
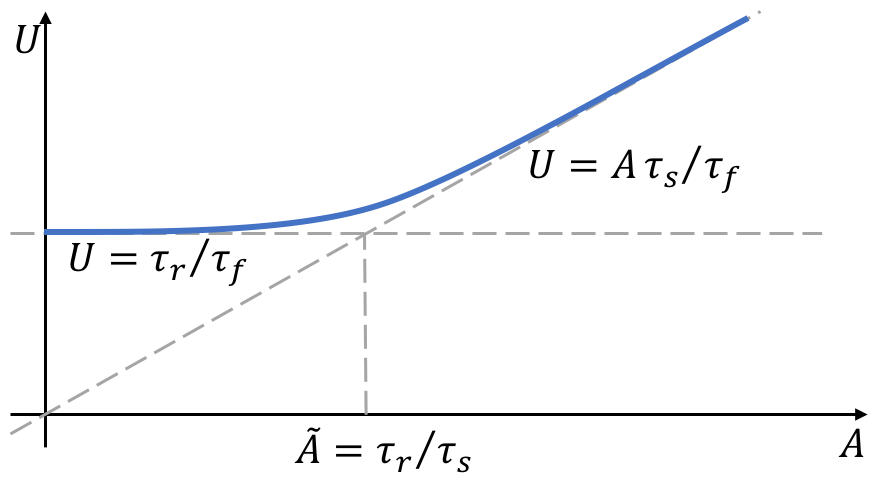
You can only see a linear dependency from the first graph, but it will not answer the question: "What do you need to do to improve the situation?" The second picture describes a more complex model that can immediately provide answers to questions about what to do and how to improve the behavior of the replication process. Moreover, it provides a recipe for a quick way, literally in mind, estimating the effects of some architectural decisions. In other words, the predictive strength of the developed model is at a qualitatively different level.
Chunk Loss
Now let's obtain the typical time of chunk loss. To do this, we write out the kinetics of the processes of formation of such chunks taking into account the replication factor 3:
Here
Where
For the case
That is, the typical time of the formation of the lost chunk is 100 million years! There are roughly similar values for the mentioned two cases as we are in the transition zone. The typical time value
It is worth mentioning one thing, however. In the case

Conclusion
The article consistently introduces an innovative way of simulating the kinetics of large cluster processes. The approximate model for describing the dynamics of a cluster can be considered as probabilistic characteristics that describe the data loss.
Of course, this model is only the first approximation to what is actually happening on the cluster. Here we have only taken into account the most important processes in order to produce a qualitative result. But even such a model allows you to judge what is happening within the cluster and also provides recommendations to improve the situation.
However, the suggested approach allows for more accurate and reliable results based on a subtle consideration of different factors and an analysis of the actual performance of the cluster. Below is a far from the exhaustive list for improving the model:
- Cluster nodes can fail due to various hardware failures. The failure of a particular node usually has a different probability. Moreover, a failure, for example, of a processor, does not lose data, but only gives a temporary inaccessibility of the node. It is easy to take into account in the model, introducing different states
, , etc, with different process rates and different consequences. - Not all nodes are equally useful. Different batches may have different natures and frequency of failures. This can be taken into account in the model by introducing
, , and so on, at different rates of the corresponding processes. - The addition of different types of nodes to the model: partially damaged discs, banned, etc. For example, you can analyze the impact of shutting down a rack and determining the typical speeds of a cluster's transition to a steady mode. In doing so, the dynamics of chunks and nodes can be visualized by numerically solving differential equations.
- Each storage disk has slightly different read/write characteristics, including latency and bandwidth. However, you can estimate more accurately the rate constants of the processes by integrating the corresponding disk-specific distribution functions by analogy with the velocity constants in the gases, which are integrated over Maxwell–Boltzmann distribution.
Thus, on the one hand, the kinetic approach allows simplify the description and analysis, and on the other hand, has a very serious potential for introducing additional subtle factors and processes based on the analysis of cluster working data, adding specific details on demand. You can evaluate the impact of each factor's contribution to the resulting equations, allowing you to simulate improvements to make them useful. In the simplest case, this model enables you to quickly get analytical dependencies by providing recipes to improve the situation. The simulation can be bi-directional in nature: You can iteratively improve the model by adding processes to the kinetic equation system and try to analyze the potential system improvements by entering processes in the model. That is, to simulate improvements before the expensive changes by direct implementing them in your code and hardware.
In addition, it is always possible to move to numerical integration of stiff nonlinear differential equations obtaining the dynamic of the system and response to specific effects or small perturbations.
Thus, a synergy of seemingly unrelated fields of knowledge can produce astonishing results with indisputable predictive power.
References
[1] Cap Theorem Myths.
[2] Spanner, TrueTime and the CAP Theorem.
[3] The probability of data loss in large clusters.
[4] Chemical kinetics.
[5] Activated complex.
[6] Steady state approximation.
[7] Maxwell–Boltzmann distribution.
Your work is amazing. You should publish it in a peer reviewed journal.
ReplyDeleteI agree.
Delete