
Preface
This article is a continuation of the series of articles about asynchrony:
- Asynchronous Programming: Back to the Future.
- Asynchronous Programming Part 2: Teleportation through Portals.
After 3 years, I have decided to expand and generalize the available spectrum of asynchronous interaction based on coroutines. In addition to these articles, it is also recommended to read the article related to god adapter:
Introduction
Consider an electron. What do we know about it? A negatively charged elementary particle, a lepton having some mass. This means that it can participate in at least electromagnetic and gravitational interactions.
If we place a spherical electron in a vacuum, then everything that it will be able to do is moving rectilinearly. 3 degrees of freedom and spin, and only uniform rectilinear motion. Nothing interesting and unusual.
Everything changes in quite an amazing way, if other particles are nearby. For example, a proton. What do we know about it? Many things. We will be interested in the mass nature and the presence of a positive charge, modulo equal to exactly the electron, but with a different sign. This means that the electron and proton will interact with each other in an electromagnetic manner.

The result of this interaction will be the curvature of the rectilinear trajectory under the action of electromagnetic forces. But this is the half of trouble. The electron, moving nearby to the proton, will experience acceleration. The electron-proton system will be a dipole, which suddenly starts producing bremsstrahlung generating electromagnetic waves propagating in a vacuum.
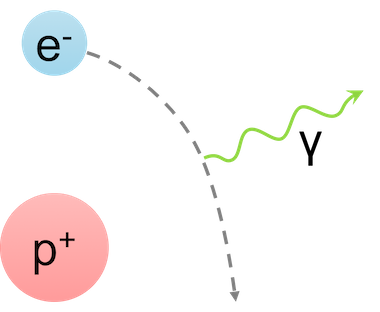
But that's not all. Under certain circumstances, the electron is captured into the proton orbit and the known system, the hydrogen atom appears. What do we know about such system? Quite a lot. In particular, this system has a discrete set of energy levels and a line spectrum of radiation, formed during the transition between each pair of stationary states.

And now let's take a look at this picture from a different angle. Initially, we had two particles: a proton and an electron. The particles themselves do not radiate (they simply can not), they do not exhibit any discreteness, and generally, behave in a relaxed manner. But the picture changes dramatically when they find each other. There are new, completely unique properties - continuous and discrete spectrum, stationary states, the minimum energy level of the system. In reality, of course, everything is much more complicated and interesting:

Asymmetric Stark broadening of the Hβ, hydrogen atom, Phys. Rev. E 79 (2009)
These arguments can be continued. For example, if you put two hydrogen atoms close together, you get a stable configuration called a hydrogen molecule. Here, electron-vibrational-rotational energy levels are appeared with specific changes in the spectrum, the appearance of P, Q, R branches and much more.
How so? Is not the system described by its parts? No! This is the essence of the fact that when the physical system becomes more complex, qualitative changes occur, not described in each part separately.
The synergy of interaction is manifested in many areas of scientific knowledge. That is why chemistry is not reduced to physics, and biology to chemistry. Despite the most powerful achievements of quantum mechanics, nevertheless, chemistry as a branch of scientific knowledge exists separately from physics. It is interesting to note the fact that there are areas of knowledge at the intersection of science, for example, quantum chemistry. What does it say? With the complication of the system, new areas of research appear that were not at the previous level. We have to take into account new circumstances, introduce additional qualitative factors, complicating each time an already difficult model for describing the quantum mechanical system.
The described metamorphoses can be reversed: if it is necessary to obtain a complex system obtained from the simplest components, then these components should have a synergistic principle. In particular, we all know that any problem can be solved by introducing an additional level of abstraction. Except for the problem of the number of abstractions and the resulting complexity. And only the synergy of abstractions makes it possible to reduce their number.
Unfortunately, quite often our programs do not show the described synergistic properties. Unfortunately, it is not true for bugs: there are new, hitherto unprecedented glitches, which were not detected in the previous stage. And I would like, that the application was not described by a set of parts and libraries of the program, but was something unique and grandiose.
Let's now try to get into the essence of OOP and coroutines for obtaining new and surprising properties of their synthesis with the purpose of creating a generalized interaction model.
Object-Oriented Programming
Let's consider OOP. What do we know about it? Encapsulation, inheritance, polymorphism? SOLID principles? And let's ask Alan Kay, who introduced this concept:
Actually I made up the term "object-oriented", and I can tell you I did not have C++ in mind.
Alan Kay.
This is a serious blow for C++ programmers. I felt sad for the language. But what did he mean? Let's sort out.
The concept of objects was introduced in the mid-1960s with the appearance of the Simula-67 language. This language introduced concepts such as an object, virtual methods and coroutines (!). Then in the 1970s, the Smalltalk language, influenced by Simula-67, enhanced the idea of objects and introduced the term object-oriented programming. It was there that the foundations of what we now call the OOP were laid. Alan Kay himself had commented on his sentence:
I'm sorry that I long ago coined the term "objects" for this topic because it gets many people to focus on the lesser idea. The big idea is "messaging".
Alan Kay.
If you remember Smalltalk, it becomes clear what it means. This language uses the sending of messages (see also Objective-C). This mechanism worked, but it was rather slow. Therefore, in the future, we followed the path of the Simula language and replaced the sending of messages to ordinary function calls, as well as calls to virtual functions through a table of these virtual functions to support runtime binding.
To return to the origins of OOP, let's take a fresh look at classes and methods in C++. To do this, let's consider the Reader class that reads data from a source and returns a Buffer object:
class Reader
{
public:
Buffer read(Range range, const Options& options);
// and other methods...
};
In this case, I will only be interested in the read method. This method can be converted to the next, almost equivalent, call:
Buffer read(Reader* this,
Range range,
const Options& options);
We simply turned the method call of an object into a stand-alone function. This is what the compiler is doing when it compiles our code into machine code. However, this way leads us to the opposite way, to be precise, in the direction of the C language. Here the OOP does not smell even close, so let's go the other way.
How do we call the read method? For example:
Reader reader;
auto buffer = reader.read(range, options);
Let's transform the read method call as follows:
reader
<- read(range, options)
-> buffer;
This code means the following. An object named reader has the input read(range, options), and on the output, the reader provides an object buffer.
What can be read(range, options) and buffer? Some input and output messages:
struct InReadMessage
{
Range range;
Options options;
};
struct OutReadMessage
{
Buffer buffer;
};
reader
<- InReadMessage{range, options}
-> OutReadMessage;
This transformation gives us a slightly different understanding of what is happening: instead of calling a function, we synchronously send an InReadMessage message and then wait for the response message of OutReadMessage. Why synchronously? Because the semantics of the call implies that we are waiting for an answer at the point of invocation. However, generally speaking, the response message in the place of a call may not wait, then it will be an asynchronous sending the message.
Thus, all methods can be represented as handlers of different types of messages. And our object automatically dispatches received messages, carrying out static pattern matching through the mechanism of the declaration of various methods and overloading of the same methods with different types of input parameters.
Message Interception and Action Transformation
We will work on our messages. How can we pack a message for the followed transformation? For that purpose we will use the adapter:
template<typename T_base>
struct ReaderAdapter : T_base
{
Buffer read(Range range, const Options& options)
{
return T_base::call([range, options](Reader& reader) {
return reader.read(range, options);
});
}
};
Now, when the read method is called, the call is wrapped in a lambda and transferred to the T_base::call of the base class. In this case, a lambda is a functional object that will pass its closure to our descendant object T_base, automatically dispatching it. This lambda is our message, which we pass on transforming the actions.
The simplest way to apply the transformation is to synchronize access to the object:
template<typename T_base, typename T_locker>
struct BaseLocker : private T_base
{
protected:
template<typename F>
auto call(F&& f)
{
std::unique_lock<T_locker> _{lock_};
return f(static_cast<T_base&>(*this));
}
private:
T_locker lock_;
};
Inside the call method, locking lock_ takes place and a subsequent lambda is called on an instance of the base class T_base, which allows further transformations, if necessary.
Let's try to use this functionality:
// create instance
ReaderAdapter<BaseLocker<Reader, std::mutex>> reader;
auto buffer = reader.read(range, options);
What's going on here? Instead of using the Reader directly, we now replace the object with the ReaderAdapter template. This adapter, when calling the read method, creates a message in the form of a lambda and passes it on, where the lock is already automatically taken and released strictly for the duration of this operation. At the same time, we exactly preserve the original interface of the Reader class!
This approach can be generalized by using a god adapter.
The corresponding code with the god adapter will look like this:
DECL_ADAPTER(Reader, read)
AdaptedLocked<Reader, std::mutex> reader;
Here the adapter intercepts each method of the Reader class specified in the DECL_ADAPTER list, in this case, read method, and then AdaptedLocked adapts already intercepted message by applying locking synchronization based on std::mutex. More details about this are described in the above-mentioned article, so here I will not consider the approach in detail.
Coroutines
We have considered OOP and obtained a little understanding. Now let's go from the other side and talk about coroutines.
What are coroutines? In short, these are functions that can be interrupted at any place, and then can be continued from that place, i.e. freeze the current execution and restore it from the suspended point. In this sense, they are very similar to threads: the operating system can also freeze them at any time and switch to another thread. For example, because we consume too much CPU time.
But what is the difference between threads and coroutines then? The difference is that we can switch between our coroutines in the user space at any time by ourselves without involving the kernel. Firstly, that increases the performance, because there is no need to switch processor rings, contexts etc., and secondly, to add more interesting ways of interaction, which will be discussed below in detail.
Some interesting ways of interaction can be read in my previous articles about asynchrony.
CoSpinLock
Consider the following piece of code:
namespace synca {
struct Spinlock
{
void lock()
{
while (lock_.test_and_set(std::memory_order_acquire)) {
reschedule();
}
}
void unlock()
{
lock_.clear(std::memory_order_release);
}
private:
std::atomic_flag lock_ = ATOMIC_FLAG_INIT;
};
} // namespace synca
The above code looks like an ordinary spinlock. Indeed, inside the lock method, we are trying to atomically switch the flag value from false to true. If we succeeded, then the lock is taken, and it was taken by current execution, so it is possible to perform the necessary atomic actions under the obtained lock. On unlocking, we simply reset the flag back to the initial value false.
All the difference lies in the implementation of the backoff strategy. Either an exponential randomized backoff or the transfer of control to the operating system via std::this_thread::yield() are often used. The code above is a bit trickier: instead of warming up the processor or transferring control to the operating system's scheduler, I simply reschedule our coroutine to a later execution via the synca::reschedule invocation. At the same time, the current execution becomes frozen, and the scheduler launches another coroutine ready for execution. This is very similar to std::this_thread::yield(), except that instead of switching to kernel space, we are keeping execution in user space and continue to do some meaningful work without increase of entropy of space.
Adapter application is the following:
template <typename T>
using CoSpinlock = AdaptedLocked<T, synca::Spinlock>;
CoSpinlock<Reader> reader;
auto buffer = reader.read(range, options);
As you can see, the code usage and semantics have not been changed, but the behavior has been changed.
CoMutex
The same trick can be performed with an ordinary mutex, turning it into an asynchronous one based on coroutines. To do this, you should add the waiting queue of coroutines and start them sequentially at the time the lock is released. This can be illustrated by the following scheme:

I'm not going to provide the full implementation code here. Those who wish can read it independently. I will give only the usage example:
template <typename T>
using CoMutex = AdaptedLocked<T, synca::Mutex>;
CoMutex<Reader> reader;
auto buffer = reader.read(range, options);
Such mutex has the semantics of a regular mutex, but it does not block the thread execution, forcing the coroutine scheduler to perform useful work without switching to kernel space. CoMutex, unlike CoSpinlock, provides a FIFO-guarantee, i.e. provides fair concurrent access to the object.
CoSerializedPortal
In the article Asynchrony 2: Teleportation Through Portals, the task of switching context between different schedulers through the use of teleportation and portals was considered in detail. Here I briefly describe the mentioned approach.
Consider an example where we need to switch the coroutine from one thread to another. For this, we can freeze the current state of our coroutine in the source thread, and then schedule the coroutine by resuming it in another thread:

This is exactly what corresponds to switching execution from one thread to another. The program provides an additional level of abstraction between the code and the thread, allowing you to manipulate the current execution and perform various tricks. Switching between different schedulers is known as teleportation.
If we need to switch to another scheduler first, and then go back - then portal appears. The portal constructor teleports to destination scheduler, and destructor teleports to the original one. This portal object guarantees a return to the original execution context even in case of thrown exception due to RAII semantics.
Accordingly, there is a simple idea: create a single threaded scheduler and reschedule our coroutines through portals:
template <typename T_base>
struct BaseSerializedPortal : T_base
{
// create thread pool with single thread
BaseSerializedPortal() : tp_(1) {}
protected:
template <typename F>
auto call(F&& f)
{
// Portal constructor teleports to created scheduler
synca::Portal _{tp_};
return f(static_cast<T_base&>(*this));
// Portal destructor returns back to original scheduler
}
private:
mt::ThreadPool tp_;
};
CoSerializedPortal<Reader> reader;
It is clear that used scheduler will serialize our actions, and therefore synchronize them with each other. In this case, if the thread pool provides FIFO-guarantees, then CoSerializedPortal will have the same guarantee.
CoAlone
The previous approach with portals can be used somewhat differently. To do this, we will use another scheduler: synca::Alone.
This scheduler has the following wonderful property: at any time, no more than one task of this scheduler can be executed. Thus, synca::Alone guarantees that no handler will be started in parallel with the other. If there are tasks then only one of them will be executed. If there is no task then nothing happens. It is clear that this approach serializes the actions, which means that access through this scheduler will be synchronized. Semantically, it's very similar to CoSerializedPortal. It should be noted, however, that such scheduler runs its tasks on a certain thread pool, i.e. it does not create any new threads on its own, but works on existing ones.
For more details, I recommend the reader to look through the original article Asynchrony 2: Teleportation Through Portals.
template <typename T_base>
struct BaseAlone : T_base
{
BaseAlone(mt::IScheduler& scheduler)
: alone_{scheduler} {}
protected:
template <typename F>
auto call(F&& f)
{
// Alone is scheduler thus we reuse Portal
synca::Portal _{alone_};
return f(static_cast<T_base&>(*this));
}
private:
synca::Alone alone_;
};
CoAlone<Reader> reader;
The only difference in implementation compared to CoSerializedPortal is the replacement of the mt::ThreadPool by synca::Alone.
CoChannel
Let's introduce the concept of the channel based on coroutines. Ideologically, it is similar to the channels in Go language, i.e. it is a queue (not necessarily, by the way, the bounded queue as it is implemented in Go), where multiple producers can put the data into the queue and multiple consumers can extract the data simultaneously without additional synchronization. Simply, the channel is just a pipe into which you can add and then extract the messages without the race condition.
The idea of using the channel is that users of our objects write messages to the channel, and the consumer is a specially created coroutine that reads out messages in an infinite loop and dispatches it into the appropriate method.
template <typename T_base>
struct BaseChannel : T_base
{
BaseChannel()
{
// create coroutine and run message loop
synca::go([&] { loop(); });
}
private:
void loop()
{
// message loop,
// it automatically breaks on channel closing
for (auto&& action : channel_) {
action();
}
}
synca::Channel<Handler> channel_;
};
CoChannel<Reader> reader;
There are two questions: the first and the second.
- What is
Handler? - Where are dispatching and pattern matching?
Handler is just std::function<void()>. All the magic does not happen here, but how this Handler is created for automatic dispatching.
template <typename T_base>
struct BaseChannel : T_base
{
protected:
template <typename F>
auto call(F&& f)
{
// intercept the call and write it to fun
auto fun = [&] { return f(static_cast<T_base&>(*this)); };
// crutched result of a function call
WrappedResult<decltype(fun())> result;
channel_.put([&] {
try {
// write the result in case of no exceptions
result.set(wrap(fun));
} catch (std::exception&) {
// otherwise write the catched exception
result.setCurrentError();
}
// wake up the suspended coroutine
synca::done();
});
// suspend to wait for the result
synca::wait();
// either return the result or throw catched exception
return result.get().unwrap();
}
};
Here, fairly simple actions occur: the intercepted method call inside the f functor is wrapped in WrappedResult, the call is put to the channel and the current coroutine freezes. We call this pending call inside the BaseChannel::loop method, thereby filling the result and resuming the suspended coroutine.
It is worth saying a few words about the WrappedResult class. This class serves several purposes:
- It allows you to store either the result of the call or the caught exception.
- In addition, he solves the following problem. The point is that if the function does not return any values (that is, returns the type
void), then the construction with the assignment of the result without the wrapper would be incorrect. Indeed, you can not just writevoidto thevoidvariable. However, it is allowed to usevoidtype together withreturn, which is used by theWrappedResult<void>specialization through invocation.get().unwrap().
As a result, we have synchronized access to any object method through the channel handler with the captured method arguments. In this case, all methods are processed in a separate, isolated coroutine, which ensures the serialized execution of the handlers mutating the object state.
Ordinary Asynchrony
Let's try, for the sake of interest, to implement the same behavior without the adapter and coroutines in order to demonstrate most clearly all the power and strength of the applied abstractions.
To do this, consider the implementation of an asynchronous spinlock:
struct AsyncSpinlock
{
void lock(std::function<void()> cb)
{
if (lock_.test_and_set(std::memory_order_acquire)) {
// lock was not granted => reschedule it
currentScheduler().schedule(
[this, cb = std::move(cb)]() mutable {
lock(std::move(cb));
});
} else {
cb();
}
}
void unlock()
{
lock_.clear(std::memory_order_release);
}
private:
std::atomic_flag lock_ = ATOMIC_FLAG_INIT;
};
Here the standard interface of the spinlock has changed. This interface has become more cumbersome and less enjoyable.
Now implement the AsyncSpinlockReader class, which will use our asynchronous spinlock:
struct AsyncSpinlockReader
{
void read(Range range, const Options& options,
std::function<void(const Buffer&)> cbBuffer)
{
spinlock_.lock(
[this, range, options, cbBuffer = std::move(cbBuffer)] {
auto buffer = reader_.read(range, options);
// it's cool that unlock is synchronous
// otherwise we could see funny ladder of lambdas
spinlock_.unlock();
cbBuffer(buffer);
});
}
private:
AsyncSpinlock spinlock_;
Reader reader_;
}
As we see from the read method, the asynchronous spinlock AsyncSpinlock will necessarily break existing interfaces of our classes.
And now consider the use of:
// instead of
// CoSpinlock<Reader> reader;
// auto buffer = reader.read(range, options);
AsyncSpinlockReader reader;
reader.read(buffer, options, [](const Buffer& buffer) {
// buffer is transferred as an input parameter
// we need to carefully transfer the execution context here
});
Let's assume for a minute that Spinlock::unlock and the Reader::read method are also asynchronous. In this, it is easy enough to believe, if we assume that the Reader pulls data over the network, and instead of Spinlock, for example, portals are used. Then:
struct SuperAsyncSpinlockReader
{
// error handling is deliberately omitted here,
// otherwise the brain will change its state of aggregation
void read(Range range, const Options& options,
std::function<void(const Buffer&)> cb)
{
spinlock_.lock(
[this, range, options, cb = std::move(cb)]() mutable {
// the first fail: read is asynchronous
reader_.read(range, options,
[this, cb = std::move(cb)](const Buffer& buffer) mutable {
// the second fail: spinlock is asynchronous
spinlock_.unlock(
[buffer, cb = std::move(cb)] {
// the end of cool ladder
cb(buffer);
});
});
});
}
private:
AsyncSpinlock spinlock_;
AsyncNetworkReader reader_;
}

Such a straightforward approach seems to hint that it will only get worse because the working code tends to grow and becomes more complicated.
Naturally, the correct approach using coroutines makes such a synchronization scheme simple and understandable.
Non-Invasive Asynchrony
All considered synchronization primitives are implicitly asynchronous. The matter is that in case of the already locked resource with concurrent access our coroutine suspends to wake up at the moment of releasing the locking by another coroutine. If we used the so-called stackless coroutines, which are still marinated in the new standard, we would have to use the keyword co_await. And this, in turn, means that each (!) call of any method wrapped through the synchronization adapter should add co_await, changing the semantics and interfaces:
// no synchronization
Buffer baseRead()
{
Reader reader;
return reader.read(range, options);
}
// callback-style
// interface and semantics are changed
void baseRead(std::function<void(const Buffer& buffer)> cb)
{
AsyncReader reader;
reader.read(range, options, cb);
}
// stackless coroutines
// interface is changed, asynchronous behavior is added explicitly
future_t<Buffer> standardPlannedRead()
{
CoMutex<Reader> reader;
return co_await reader.read(range, options);
}
// stackful coroutines
// no interface changes
Buffer myRead()
{
CoMutex<Reader> reader;
return reader.read(range, options);
}
Here, when using the stackless approach, all interfaces in the call chain become broken. In this case, there can not be any transparency, because you can not just replace the Reader with CoMutex<Reader>. This invasive approach significantly limits the scope and applicability of the stackless coroutines.
At the same time, the approach of stackful coroutines completely eliminates the issue mentioned above.
Thus you have a unique choice:
- Use invasive breaking approach tomorrow (3 years, perhaps).
- Use a non-invasive and clear approach today (or rather, yesterday).
Hybrid Approaches
In addition to the above methods of synchronization, you can use the so-called hybrid approaches. The fact that part of the synchronization primitives is based on a scheduler that can be combined with a pool of threads for additional isolation of execution.
Consider the synchronization through the portal:
template <typename T_base>
struct BasePortal : T_base, private synca::SchedulerRef
{
template <typename... V>
BasePortal(mt::IScheduler& scheduler, V&&... v)
: T_base{std::forward<V>(v)...}
, synca::SchedulerRef{scheduler} // запоминаем планировщик
{
}
protected:
template <typename F>
auto call(F&& f)
{
// reschedule f(...) through the saved scheduler
synca::Portal _{scheduler()};
return f(static_cast<T_base&>(*this));
}
using synca::SchedulerRef::scheduler;
};
In the constructor of the base class of the adapter, we set the scheduler mt::IScheduler, and then reschedule our call f(static_cast<T_base&>(*this)) through the portal stored in the scheduler. To use this approach we must first create a single threaded scheduler to synchronize our execution:
// create single thread in thread pool to synchronize access
mt::ThreadPool serialized{1};
CoPortal<Reader> reader1{serialized};
CoPortal<Reader> reader2{serialized};
Thus, both Reader instances are serialized through the same thread belonging to the serialized pool.
You can use a similar approach for the isolation of execution for CoAlone and CoChannel:
// because CoAlone и CoChannel synchronize the execution,
// thus the number of threads may be arbitrary
mt::ThreadPool isolated{3};
// the synchronization will take place
// inside isolated thread pool
CoAlone<Reader> reader1{isolated};
// to read from the channel the coroutine will be created
// inside isolated thread pool
CoChannel<Reader> reader2{isolated};
Subjector
So, we have 5 different ways of non-blocking effective synchronization of object operations in the user space:
CoSpinlock.CoMutex.CoSerializedPortal.CoAlone.CoChannel.
All of these methods provide uniform access to the object. Let's take the final step to generalize the resulting code:
#define BIND_SUBJECTOR(D_type, D_subjector, ...) \
template <> \
struct subjector::SubjectorPolicy<D_type> \
{ \
using Type = D_subjector<D_type, ##__VA_ARGS__>; \
};
template <typename T>
struct SubjectorPolicy
{
using Type = CoMutex<T>;
};
template <typename T>
using Subjector = typename SubjectorPolicy<T>::Type;
Here we create a type Subjector<T> that can later be specified by using one of the 5 behaviors. For example:
// assume that Reader has 3 methods: read, open, close
// create adapter to intercept those methods
DECL_ADAPTER(Reader, read, open, close)
// then define that Reader must use CoChannel
// if we omit this line CoMutex will be used by default
// thus this line is optional
BIND_SUBJECTOR(Reader, CoChannel)
// here we use an already configured subjector -
// universal synchronization object
Subjector<Reader> reader;
If we want to use Reader, for example, in the isolated thread, then we only need to change one line:
BIND_SUBJECTOR(Reader, CoSerializedPortal)
This approach makes it possible to fine-tune the method of interaction after writing and completing the code and allows you to concentrate on issues of the day.
If you’re using early-binding languages as most people do, rather than late-binding languages, then you really start getting locked in to stuff that you’ve already done. You can’t reformulate things that easily.
Alan Kay.
Asynchronous Call
The above synchronization primitives utilized nonblocking synchronous invocation. Thus every time we are waiting for the task completion obtaining the result. This corresponds to the common semantics of object method calls. However, in some scenarios, it is useful to explicitly start a task asynchronously, without waiting for the result in order to parallelize the execution.
Consider the following example:
class Network
{
public:
void send(const Packet& packet);
};
DECL_ADAPTER(Network, send)
BIND_SUBJECTOR(Network, CoChannel)
If we use the code:
void sendPacket(const Packet& packet)
{
Subjector<Network> network;
network.send(myPacket);
// the next action will not start
// until the previous one is completed
doSomeOtherStuff();
}
then the action doSomeOtherStuff() does not start until the end of the execution network.send(). The following code can be used to asynchronously send a message:
void sendPacket(const Packet& packet)
{
Subjector<Network> network;
// call using .async()
network.async().send(myPacket);
// next action will execute in parallel
// with the previous one
doSomeOtherStuff();
}
And voila - synchronous code turned into an asynchronous!
It works like this. First, a special asynchronous wrapper for the adapter BaseAsyncWrapper is created by using strange recursive template pattern:
template <typename T_derived>
struct BaseAsyncWrapper
{
protected:
template <typename F>
auto call(F&& f)
{
return static_cast<T_derived&>(*this).asyncCall(std::forward<F>(f));
}
};
The call .async() is redirected to BaseAsyncWrapper that forwards the call back to the child class T_derived, but through the use of a method asyncCall instead of call. Thus, for our Co-objects, the method is sufficient to implement asyncCall in addition to call obtaining asynchronous functionality automatically.
To implement asyncCall all the synchronization methods can be divided into two classes:
- Initially synchronous call:
CoSpinlock,CoMutex,CoSerializedPortal,CoAlone. To do this, we simply create a new coroutine and run our action on a given scheduler.
template <typename T_base>
struct Go : T_base
{
protected:
template <typename F>
auto asyncCall(F&& f)
{
return synca::go(
[ f = std::move(f), this ]() {
f(static_cast<T_base&>(*this));
},
T_base::scheduler());
}
};
- Initially asynchronous call:
CoChannel. For this purpose, it is necessary to remove suspending/resuming and leave the original asynchronous call.
template <typename T_base>
struct BaseChannel : T_base
{
template <typename F>
auto asyncCall(F&& f)
{
channel_.put([ f = std::move(f), this ] {
try {
f(static_cast<T_base&>(*this));
} catch (std::exception&) {
// do nothing due to async call
}
});
}
};
Characteristics
Various characteristics of these approaches are summarized in the following table:
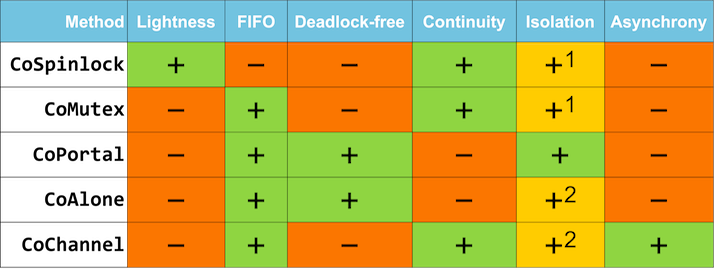
1Using asynchronous call simultaneously with the hybrid approach.
2Using the hybrid approach.
Let's consider each column in detail.
Lightness
CoSpinlock is definitely the most lightweight entity under consideration. Indeed, it contains only atomic instructions and coroutine rescheduling in the case of the locked resource. CoSpinlock makes sense to use in situations of small locking time because otherwise, it starts loading the scheduler useless work to check the atomic variable with subsequent rescheduling. Other synchronization primitives use more heavyweight implementation to synchronize their objects, but do not load the scheduler in case of conflict.
FIFO
FIFO, or first-in-first-out guarantee, is a guarantee of the queue. It is worth mention that if the application has the only scheduler and that scheduler provides a FIFO-guarantee, CoSpinlock does not give the FIFO-guarantee even in this case.
Deadlock-free
As the name implies, this synchronization primitive never leads to deadlocks. This guarantee is provided by scheduler-based primitives.
Continuity
By this notion, I mean the continuity of the lock taken, as if the synchronization has been done by using a mutex. It turns out that continuity is closely connected with the property of deadlock-free. I would like to describe this topic in more details below, as it is important for the deep understanding of synchronization methods and represents particular practical interest.
Isolation
The isolation property has already been used partially when CoPortal has been considered. Isolation is the property to execute a method in an isolated thread pool. Only CoSerializedPortal uses this property by default since it creates a thread pool with a single thread to synchronize execution. In synchronous execution, as has been previously discussed, such a property can also have primitives based on scheduler: CoAlone and CoChannel. In case of asynchronous invocation, the execution has been forked. This task is solved by a scheduler, which means there is a possibility of isolation of the code and other methods.
Asynchrony
All methods, except for CoChannel use the current coroutine to run a synchronized action. Only CoChannel runs the operation in parallel and waits for the result. Thus the native method of execution for this synchronization primitive is an asynchronous task invocation. It means that CoChannel provides a better opportunity for:
- Parallel: effectively executes the various processing steps.
- Maintain the object context: a minimum of context switches for the synchronized object, object data is not flushed out of the cache of the processor, speeding up processing.
Deadlocks and Race Conditions
I like to ask the following problem.
Problem 1. Suppose that all the methods of our class synchronized via the mutex. Immediately the question appears: is it possible to obtain the race condition?

The obvious answer is no. However, there is a certain catch. The idea starts spinning in the head, the brain begins to offer crazy options, do not meet the conditions of the problem. As a result, everything turns to ashes and hopelessness appears.
I advise you to think carefully before seeing the answer. But to avoid breaking the brain, I provide a solution for this problem below.
Consider the following class:
struct Counter
{
void set(int value);
int get() const;
private:
int value_ = 0;
};
Wrap it:
DECL_ADAPTER(Counter, set, get)
Subjector<Counter> counter;
Methods get and set will be wrapped by the asynchronous mutex, even though asynchronous here is not essential. Synchronization is important.
And now we want to solve the problem:
Problem 2. Atomically increment the counter.
And then many suddenly realize:
counter.set(counter.get() + 1);
This code contains the race condition, despite the fact that each call individually synchronized!
To understand the diversity of different race conditions it makes sense to introduce the following categories.
Race Condition of the First Kind
Or data race, as described in the standard:
The execution of a program contains a data race if it contains two potentially concurrent conflicting actions, at least one of which is not atomic, and neither happens before the other, except for the special case for signal handlers described below. Any such data race results in undefined behavior.
A typical example of this case - when there are two actions that change the object state without any synchronization that is performed in two different threads, for example std::vector::push_back(value). In the best case, the program will crash, in the worst case, it secretly corrupts the data (yes, in this case, the early crash is the best option). To catch such hard problems, there are special tools:
- ThreadSanitizer: allows to detect problems at runtime.
- Helgrind: a thread error detector: Valgrind tool for detecting synchronization errors.
- Relacy race detector: verifies the multithreaded lock-free/wait-free algorithms based on the memory model.
Race Condition of the Second Kind
Any race conditions which do not fall under the first category are race conditions of the second kind. These higher-level conditions, which are described by the logic of the program and its invariants, so they can not be detected by low-level tools and verifiers mentioned above. They typically demonstrate an atomicity break as it was shown in the example above with a counter counter.set(counter.get() + 1). This is due to the fact that .get(), and .set() synchronized separately.
At the moment, the tools for the analysis of such issues at an early stage of development. Below is a short list of minimal comments because a detailed description is beyond the scope of this article:
- Node.fz: fuzzing the server-side event-driven architecture: researchers found bugs related to the concurrent interaction in single-threaded asynchronous code!
- An empirical study on the correctness of formally verified distributed systems: the study of the correctness of formal verified systems. Authors found bugs where they should not be in principle!
Continuity and Asynchrony
The addition of the asynchronous behavior can provide the unexpected program execution, which leads to a tremendous opportunity wonder incorrect behavior once again. For this we consider synchronization via CoAlone:
struct User
{
void setName(const std::string& name);
std::string getName() const;
void setAge(int age);
int getAge() const;
};
DECL_ADAPTER(User, setName, getName, setAge, getAge)
BIND_SUBJECTOR(User, CoAlone)
struct UserManager
{
void increaseAge()
{
user_.setAge(user_.getAge() + 1);
}
private:
Subjector<User> user_;
};
UserManager manager;
// race condition of the 2nd kind
manager.increaseAge();
Here the line manager.increaseAge() contains already known race condition of the 2nd kind, leading to inconsistency in the case of the concurrent behavior of the method call increaseAge() in two different threads.
You can try to fix this behavior:
struct UserManager
{
void increaseAge()
{
user_.setAge(user_.getAge() + 1);
}
private:
Subjector<User> user_;
};
DECL_ADAPTER(UserManager, increaseAge)
BIND_SUBJECTOR(UserManager, CoAlone)
Subjector<UserManager> manager;
manager.increaseAge();
We use CoAlone for synchronization in both cases. The question immediately arises: Will the race condition in this case?

Will be! Despite the additional synchronization, this example is also subject to the problem of the race condition of the 2nd kind. Indeed, when you synchronize UserManager the current coroutine runs on the scheduler Alone. Then the call user_.getAge() teleports to another scheduler Alone belonging to User. So another running coroutine now is able to enter into the method increaseAge() in parallel with the current, which at this point is inside user_.getAge(). This is possible because Alone guarantees only the absence of parallel execution in its scheduler. In this scenario, we have the parallel execution of two different schedulers: CoAlone<User> and CoAlone<UserManager>.
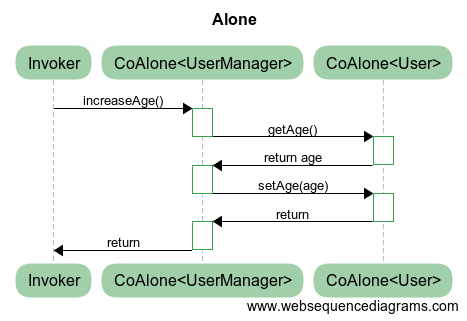
Thus, atomic execution breaks in the case of scheduler-based synchronization: CoAlone and CoPortal.
To fix this situation, it is sufficient to replace:
BIND_SUBJECTOR(UserManager, CoMutex)

This will prevent the race condition of the 2nd kind.
Execution Continuity
In some cases, the break of atomic execution is extremely useful. To do this, consider the following example:
struct UI
{
// triggered when user requests the info
void onRequestUser(const std::string& userName);
// update the user info in UI
void updateUser(const User& user);
};
DECL_ADAPTER(UI, onRequestUser, updateUser)
// UI attaches to the main UI thread
BIND_SUBJECTOR(UI, CoPortal)
struct UserManager
{
// request the user info
User getUser(const std::string& userName);
private:
void addUser(const User& user);
User findUser(const std::string& userName);
};
DECL_ADAPTER(UserManager, getUser)
BIND_SUBJECTOR(UserManager, CoAlone)
struct NetworkManager
{
// request the info from remote server
User getUser(const std::string& userName);
};
DECL_ADAPTER(NetworkManager, getUser)
// network actions are executed outside the other threads isolated
BIND_SUBJECTOR(NetworkManager, CoSerializedPortal)
// functions returning singletons of objects
Subjector<UserManager>& getUserManager();
Subjector<NetworkManager>& getNetworkManager();
Subjector<UI>& getUI();
void UI::onRequestUser(const std::string& userName);
{
updateUser(getUserManager().getUser(userName));
}
void UserManager::getUser(const std::string& userName)
{
auto user = findUser(userName);
if (user) {
// user has been found => return it immediately
return user;
}
// user has not been found => request it remotely
user = getNetworkManager().getUser(userName);
// add user to avoid remote call again
addUser(user);
return user;
}
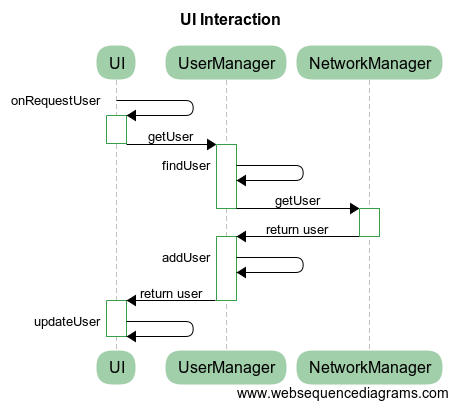
All the actions begin with the call UI::onRequestUsername. At this point, there is a call UserManager::getUser in UI thread through the corresponding subjector. This subjector first switches execution to another UI thread scheduler Alone, and then calls the corresponding method. In this case, the UI thread is unlocked and can perform other actions. Thus, the call is asynchronous and therefore does not block the UI not forcing it to slow down.
If UserManager already contains information related to the requesting user - the problem is solved, and we return it immediately. Otherwise, we will ask for the necessary information on the network through NetworkManager. Again, we do not block UserManager for the duration of a long query over the network. If at this point the user has requested some other information from the UserManager in parallel, we will be able to provide it without waiting for the completion of the initial operation! So, in this case, the break of atomic execution only improves the responsiveness and provides parallel query execution. At the same time, we made no effort to implement this strategy because subjector automagically synchronizes the access by rescheduling our coroutines appropriately. Is not this a miracle?
Deadlocks
Another unique characteristic that has scheduler-based subjectors is the absence of deadlocks. Take a look:
// forward declaration
struct User;
DECL_ADAPTER(User, addFriend, getId, addFriendId)
struct User
{
void addFriend(Subjector<User>& myFriend)
{
auto friendId = myFriend.getId();
if (hasFriend(friendId)) {
// do nothing in case of friend presence
return;
}
addFriendId(friendId);
auto myId = getId();
myFriend.addFriendId(myId);
}
Id getId() const;
void addFriendId(Id id);
private:
bool hasFriend(Id id);
};
void makeFriends(Subjector<User>& u1, Subjector<User>& u2)
{
u1.addFriend(u2);
}

Because the default subjector behavior is CoMutex, then the parallel execution of makeFriends will sometimes hang. How to avoid this situation without having to rewrite all the code from scratch? You need to just add a single line:
BIND_SUBJECTOR(User, CoAlone)
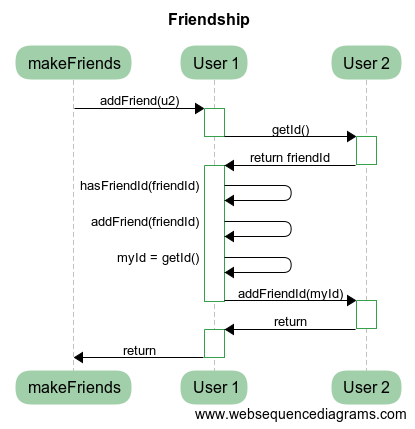
Now, no matter how you execute it and how many threads you use you will never obtain the deadlock. Could you ever imagine that it is possible? Obviously, not.
Relationship
If you look closely at the table of comparative characteristics of various ways of interactions, it is possible to see the relationship: if there is continuity then there is no deadlock-free, and vice versa. In general, one can show that in the case of the described methods of synchronization we cannot simultaneously achieve both properties. However, when applying special techniques of transactional execution with tracking dependencies such behavior is possible. However, it requires a separate article to be written, so it will not be considered here.
Discussion
We have obtained 5 different ways to synchronize concurrent execution. Adding 3 hybrid approaches and doubling the total result to take into account asynchronous calls we obtain 16 different variants of nonblocking asynchronous synchronization in the user space without switching to kernel space. As long as there is any work, it will be executed maximizing the loading of all the processor cores. The user may choose the way of synchronization based on the application logic and data interaction.
Among all these 16 ways there is a special case that has a lot of popularity nowadays: CoChannel<T>.async().someMethod(...). Such interaction applied to all participants in the process is called the actor model. Indeed, the channel is the mailbox that automatically dispatches incoming messages that match the methods of a class, using the power of C++ including static type system, OOP, and macros based template meta-programming. Despite the fact that actor model does not require additional synchronization it is subject to race conditions of the second kind, which in turn eliminates deadlocks.
Introduced subjector model has a much greater variability, allowing later to change the particular mode of concurrent interaction without breaking existing interfaces and implementations. The specific choice depends on the circumstances and the arguments presented in this article can be considered as a starting point for the final decision. Each of the methods has special characteristics, wherein the silver bullet has not been delivered again.
Conclusion
Here is a list of major achievements:
-
Synchronization integration. All data required for synchronization are placed inside our entity, so it converts the passive object into the active participant - subjector.
-
Deep abstraction of execution. The proposed model introduces a single abstraction through a generalized understanding of the principles of object-oriented programming. It joins together a variety of primitives, creating a universal model.
-
Non-invasiveness. Subjector does not change the original interfaces, and thus allows you to transparently add a synchronization without code refactoring.
-
Protection from a multi-threaded design mistakes. Universal adapter guarantees and automatically performs all the necessary steps required to synchronize the execution. This eliminates the necessity to annotate or comment fields and methods in the class, describing the required usage context. Subjector isolates all the available fields and class methods, preventing the huge class of the most insidious bugs associated with concurrent programming, giving the task to synchronize object access to the compiler.
-
Late optimization. Based on the data locality and the production usage pattern the developer may switch between different types of synchronization for the best results at the final stage of the application development.
-
Efficiency. The approach under consideration implements context switching exclusively in user space through the use of coroutines, which makes minimal overhead and maximum utilization of hardware resources.
-
Clarity, purity, and simplicity of the code. There is no need to explicitly use the correct tracking of synchronization context and think about how, when, and what variables should be used together with particular guards, mutexes, schedulers, threads, etc. This gives a more simple composability of different parts, allowing the developer to focus on solving specific tasks, rather than fixing the tricky issues.
As you know, the model is simplified with a generalization. The philosophy of object-oriented programming makes a different way to look at the traditional concepts and see the magnificent abstractions. The synergy of these seemingly incompatible concepts like OOP, coroutines, channels, mutexes, spinlocks, threads and schedulers creates a new model of concurrent interactions, generalizing the well-known model of the actors, the traditional model based on a mutex and a model of communicating sequential processes, blurring the line between two different ways of interaction: through shared memory and through the exchange of messages.
The name of this generalized model of concurrent interaction is subjector model.
https://github.com/gridem/Subjector

References
[1] Asynchronous Programming: Back to the Future.
[2] Asynchronous Programming Part 2: Teleportation through Portals.
[3] Replicated Object. Part 2: God Adapter.
[4] S. Djurović, M. Ćirišan, A.V Demura, G.V Demchenko, D. Nikolić, M.A. Gigosos, et al., Measurements of Hβ Stark central asymmetry and its analysis through standard theory and computer simulations, Phys. Rev. E 79 (2009) 46402.
[5] Quantum chemistry.
[6] Object-oriented design: SOLID.
[7] Simula-67 language.
[8] Smalltalk language.
[9] Objective-C language.
[10] Go by Example: Channels.
[11] Curiously recurring template pattern.
[12] C++17 Standard N4659.
[13] ThreadSanitizer.
[14] Helgrind: a thread error detector.
[15] Relacy race detector.
[16] Non-blocking algorithm.
[17] J.Davis, A.Thekumparampil, D.Lee, Node.fz: fuzzing the server-side event-driven architecture. EuroSys '17 Proceedings of the Twelfth European Conference on Computer Systems, pp 145-160.
[18] P.Fonseca, K.Zhang, X.Wang, A.Krishnamurthy, An empirical study on the correctness of formally verified distributed systems. EuroSys '17 Proceedings of the Twelfth European Conference on Computer Systems, pp 328-343.
[19] Actor model.
[20] Communicating sequential processes.
[21] Shared memory.
[22] Message passing.
You attribute several quotes to "Alan Key", when they should be attributed to Alan Kay. Understandable. I find an allen key has more useful things to say on OOP and Alan Kay.
ReplyDelete8)
DeleteFixed