
Abstract
Exactly-once data processing in real-time is an extremely non-trivial task and requires serious and thoughtful approach for the entire pipeline. Someone even believes that such a task is impossible. In reality, one wants to have an approach that provides generic fault-tolerant processing without any delays together with using the different data storages, which puts forward an even stronger requirement for the system: concurrent exactly-once and heterogeneity of the persistent layer. To date, any of the existing systems do not support this requirement.
The proposed approach will consistently reveal secret ingredients and necessary concepts allowing to implement heterogeneous concurrent exactly-once processing relatively easy literally based on two components.
Introduction
The developer of distributed systems passes several stages:
Stage 1: Algorithms. Here we study the basic algorithms, data structures, approaches to OOP type programming, and so on. The code is solely single-threaded. The initial phase of entering the profession. Nevertheless, it is rather difficult and can last for years.
Stage 2: Multithreading. Then there are questions of extracting maximum efficiency from hardware, there is multithreading, asynchrony, races, debugging, stracing, sleepless nights... Many get stuck at this stage and even start from some moment to catch an inexplicable buzz. But only a few come to understand the architecture of virtual memory and memory models, lock-free/wait-free algorithms, various asynchronous models. And almost no one ever comes to the verification of multi-threaded code.
Stage 3: Distributed programming. Here such shit happens that words cannot describe it.
It would seem that there is nothing complex. We make the transformation: many threads → many processes → many servers. But each step of transformation brings qualitative changes, and they all fall on the system, crushing it and turning it into dust.
And it's about changing the domain of error handling and having shared memory. If earlier there was always a piece of memory that was available in every thread, and if desired, in every process, now such a piece does not exist and can not be. Everything for itself, independent and proud.
Earlier, in multitheaded systems, crashed thread terminates the whole process at the same time, and it was good, because did not lead to partial failures, now partial failures become the norm and every time before each action you think: "what if?". This is so annoying and distracting from writing, in fact, the logic itself, that the code size becomes extremely large. Everything turns into spaghetti code, handling errors, state transitions, switching and saving context, recovery due to failures of one component, another component, unavailability of some services, etc. etc. Screwing the monitoring above that provides the perfect possibility to spend the endless nights with your favorite laptop.
While the multithreading approach provides the possibility of taking the mutex and shredding the shared memory in the fun. Amazing possibility!
As a result, we have that the key and battle-tested patterns were taken away, and the new ones, for replacement, were not brought for some reason, and it is similar to anecdote about how the fairy waved her wand and tank tower fell off.
Nevertheless, there is a set of proven practices and algorithms in distributed systems. However, every self-respecting developer considers his duty to reject known achievements and to push his own approach, despite the accumulated experience, a considerable number of scientific articles and academic researches. After all, if you can in algorithms and multithreading, how can you get into a mess with the distributed programming? There can not be two opinions here!
As a result, the systems are buggy, the data diverges and becomes corrupted, the services periodically become unavailable for writing, or even completely unavailable, because suddenly the node has crashed, the network connectivity loss, Java has been eating a lot of memory and GC has stuck, and many other reasons that allow you delaying the dismiss.
However, even with known and proven approaches, life does not become easier, because distributed reliable primitives are heavyweight with serious requirements imposed on the logic of the executable code. Therefore, the corners are cut off wherever possible. And, as it often happens, with the hastily cut off corners you receive the simplicity and relative scalability, but lose the reliability, availability, and consistency of a distributed system.
Ideally, I would not want to think about the fact that the system is distributed and multithreaded, i.e. work at the 1st stage (algorithms), without thinking about the 2nd (multithreading + asynchrony) and 3rd (distribution). This way of isolating abstractions would greatly enhance the simplicity, reliability, and speed up the code writing. Unfortunately, at the moment it's possible only in dreams.
Nevertheless, separate abstractions make it possible to achieve relative isolation. One of the typical examples is the use of coroutines, where instead of an asynchronous code, we get a synchronous one, i.e. go from the 2nd stage to the 1st stage, which makes it much easier to write and maintain the code.
In this article, the use of lock-free algorithms for constructing a reliable consistent distributed scalable real-time system is successively disclosed, i.e. how the lock-free achievements of the 2nd stage help in the implementation of the 3rd, reducing the problem to single-threaded algorithms of the 1st stage.
Problem Statement
This task only illustrates some important approaches and is presented as an example of introducing into the context of the problematics. It can easily be generalized to more complex cases, which will be done in the future.
Task: real-time streaming data processing.
There are two streams of numbers. The handler reads the data of these input streams and selects the last numbers for a certain period. These numbers are averaged in this time interval, i.e. in the sliding data window for a specified time. The resulting average value must be written to the output stream for subsequent processing. In addition, if the number of numbers in the window exceeds a certain threshold, then increase by one the counter in the external transactional database.

Let’s note several specific items:
- Nondeterminism. There are two sources of nondeterministic behavior: it is a reading from two streams, and also a time window. It is clear that reading can be done in different ways, and the final result will depend on the sequence of the extracted data. The time window also changes the result from run to run, because the amount of data within the windows depends on execution speed.
- Statefulness. We have the stateful handler to store a set of numbers.
- Interaction with external storage. We should update the counter value in the external database. The crucial point is that the type of external storage differs from the store of the handler state and streams.
All this, as will be shown below, seriously affects the used approaches and the possible ways of implementation.
It remains to add to the task a small trait, which immediately converts the problem from the area of extreme complexity into an impossible problem: a concurrent exactly-once guarantee is required.
Exactly-Once
Exactly-once is often treated too broadly, which emasculates the term itself, and it stops to meet the original requirements of the task. If we are talking about a system that works locally on one computer - then everything is simple: take more, throw further. But in this case we are talking about a distributed system in which:
- The number of handlers can be large: each handler works with its piece of data. At the same time, the results can be added to different places, for example, to an external database, perhaps sharded.
- Each handler can suddenly stop processing. The fault-tolerant system means the continuation of work even in case of failure of different parts of the system.
So, you need to be prepared for the handler to fail, and the other handler must pick up the work already done and continue processing.
Here the question immediately arises: what does exactly-once mean in the case of a nondeterministic handler? After all, in general, every time we restart, we receive different results. The answer is simple: for exactly-once, there is a system execution in which each input value is processed exactly once, giving the corresponding output. In this case, this execution does not have to be physically on the same node. But the result should be as if everything was processed on the same logical node without any failures.
Concurrent Exactly-Once
For more sophisticated requirements we introduce a new concept: concurrent exactly-once. The fundamental difference from "simple" exactly-once is the absence of pauses in processing as if everything was processed on the same node without any failures and without delays. In our task, we require precisely concurrent exactly-once, for the sake of simplicity to avoid considering a comparison with existing systems that are not available today.
The consequences of having such a requirement will be discussed below.
Transactions
In order for the reader to penetrate even deeper into the complexity that has arisen, let's look at the various bad scenarios that must be taken into account when developing such a system. We will also try to use a generic approach that solves the above problem in the perspective of our requirements.
The first thing that comes to mind is the need to save the state of the handler and the input and output streams. The state of the output streams is described by a simple queue of numbers, and the state of the input streams is represented by an index position. In fact, the stream is an infinite queue, and the position in the queue uniquely identifies the location.

There is the following naive implementation of processor using a data storage. At this stage, specific properties of the storage are not important. We will use Pseco language to illustrate the ideas (Pseco ≡ pseudo code):
handle(input_queues, output_queues, state): # restore stream positions input_indexes = storage.get_input_indexes() # process incoming streams using infinite loop while true: # load data from queues from the current position items, new_input_indexes = input_queues.get_from(input_indexes) # add items to the handler queue state.queue.push(items) # and update the window according to duration state.queue.trim_time_window(duration) avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary # (A) add the average to the output queue output_queues[0].push(avg) if need_update_counter: # (B) increase the counter in the external database db.increment_counter() # (C) save the state in the storage storage.save_state(state) # (D) save the indexes storage.save_queue_indexes(new_input_indexes) # (E) update the current indexes input_indexes = new_input_indexes
Here is a simple single-threaded algorithm that reads data out of the input streams and writes the desired values according to the task described above.
Let's see what happens if the node crashes at random places. It is clear that in the case of a crash at points (A) and (E) everything will be fine: either the data has not been saved yet and we will simply restore the state and continue processing on another node, or all the necessary data has already been saved and handler just continues the next step.
However, in case of a crash in all other points, unexpected troubles await us. If there is a failure at point (B), then on handler restarting we restore the state and push the same average value. In case of a crash at point (C) in addition to the duplicate of the average, a duplicated increment appears. And in case of a failure at (D) we get a non-consistent state of the handler: the state corresponds to a new time point while we read the values from the previous input stream positions.

In this case, the permutation of write operations don’t change the situation fundamentally: inconsistency and duplicates will remain. Thus, we conclude that all actions to change the state of a handler in the storage, the output queue, and the database must be performed transactionally, i.e. simultaneously and atomically using the all-or-nothing technique.
Accordingly, it is necessary to develop a mechanism so that different storages can change the states transactionally, not independently within each one, but transactionally between all the storages simultaneously. Of course, you can put our storage inside the external database, but the task assumed that the database engine and the stream processing engine are separated and work independently of each other. Here I want to consider the most difficult case because simple cases are not interesting.
Concurrent Responsiveness
Consider concurrent exactly-once in more detail. In the case of a fault-tolerant system, we require resuming processing from a certain point. It is clear that this point is the moment in the past because to preserve scalability, we can not store all the moments of state change in the present and in the future in the storage: either the last result of operations or a batch of changes are saved. This behavior immediately leads us to the fact that after the restoring of the handler state there will be some delay in the results, it will grow with the size of the batch and the size of the state.
In addition to this delay, there are also delays in the system related to loading the state to another node. Moreover, detection of a failed node also takes some time, and often nonnegligible. This is primarily due to the fact that if we put a short detection time, then frequent false positive events are possible, which will lead to various unpleasant side effects.
Thereto, with the increase in the number of handlers executed in parallel, it suddenly turns out that not all of them processes streams equally well even in the absence of failures. Sometimes latency spikes can happen to lead to delays in processing. The reason for such spikes can be various:
- Software: GC delays, memory fragmentation, allocator delays, kernel interrupts, and task scheduling, problems with device drivers.
- Hardware: disk or network high load, CPU throttling due to cooling problems, overload, etc., disk slowdown due to technical problems.
And this is far from an exhaustive list of problems that can lead to the slowdown of handlers.
Accordingly, the slowdown of the data processing is the reality with which we should deal with. Sometimes this is not a serious problem, and sometimes it is extremely important to maintain high processing speed in spite of failures or latency spikes.
Immediately the idea of system redundancy appears: for the same input dataset let's execute several handlers at once concurrently. The problem here is that in this case, duplicates and inconsistent behavior of the system can easily happen. Typically, frameworks are not designed for this behavior and assume that the number of handlers at each time point does not exceed one. Systems that allow the described duplication of the execution without violating the consistency are called concurrent exactly-once engines.
This architecture allows solving several problems at once:
- Resilience: if the node fails, the other node just continues to work as if nothing happened. There is no need for additional coordination of actions because the second handler is executed regardless of the state of the first one.
- Latency spikes elimination: the first completed handler wins providing the final result. The other handler has to pick up a new state and continue processing.
This approach, in particular, allows you to complete a difficult, hard long calculation for a more predictable time because the probability that concurrent handlers will fail is significantly less.
Probabilistic Estimation
Let's try to evaluate the advantages of the concurrency. Suppose that every day in average something happens with the handler: either processing delay or corresponding node fail. Suppose also that we prepare the batch of data in 10 seconds.
Then the probability that something will happen during the batch creation is 10 / (24 · 3600) ≃ 1e-4.
If you run two handlers concurrently, then the probability that both will fail ≃ 1e-8. So this event will come in 23 years! Yes, the system does not live that much, which means it will never happen!
At the same time, if the time to create the batch is even smaller and/or delays occur even more rarely, this result will only increase.
Thus, we come to the conclusion that the approach under consideration substantially increases the reliability of our entire system. It remains to resolve a small question only: where can one read about the recipe of developing the concurrent exactly-once system? And the answer is simple: here it is!
Semi-Transactions
For the sake of further discussion, we need to introduce the notion of a semi-transaction. The example is the easiest way to explain this notion.
Consider transferring funds from one bank account to another. A traditional approach using transactions in the Pseco language can be described as follows:
transfer(from, to, amount): tx = db.begin_transaction() amount_from = tx.get(from) if amount_from < amount: return error.insufficient_funds tx.set(from, amount_from - amount) tx.set(to, tx.get(to) + amount) tx.commit() return ok
But what if you do not have the ability to use the transactions? You can achieve the same result by using locks:
transfer(from, to, amount): # automatically releases the lock on scope exit lock_from = db.lock(from) lock_to = db.lock(to) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) db.set(to, db.get(to) + amount) return ok
This approach can lead to deadlocks because the locks can be taken using different sequences in parallel. To fix this behavior, it is enough to enter a function that simultaneously takes several locks in a deterministic sequence (for example, sorted by keys), which completely eliminates possible deadlocks.
Nevertheless, the implementation can be somewhat simplified:
transfer(from, to, amount): lock_from = db.lock(from) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) lock_from.release() # the lock is necessary because # db.set(db.get...) is not atomic lock_to = db.lock(to) db.set(to, db.get(to) + amount) return ok
This approach also makes the final state consistent, preserving invariants like preventing the situation of insufficient funds. The main difference from the previous approach is that in such an implementation we have a certain amount of time in which the accounts are in a non-consistent state. Namely, such an operation implies that the total amount of funds in the accounts does not change. In this case, there is a time gap between lock_from.release() and db.lock(to), during which the database can produce a non-consistent result: the total amount may differ from the correct one.
In fact, we split one transaction into two semi-transactions:
- The first semi-transaction does a check and withdraws the required amount from the account.
- The second semi-transaction deposits the withdrawn amount to another account.
It is clear that the splitting of the transaction into smaller ones, generally speaking, violates transactional behavior. And the example above is not an exception. However, if all the semi-transactions in the chain are fully executed, the result will be consistent with the preservation of all the invariants. This is the important property of the semi-transaction chain.
Temporarily losing some consistency, we, nevertheless, acquire another useful property: independence of operations, and, as a consequence, better scalability. Independence is manifested in the fact that the semi-transaction each time works with only one entity, reading, verifying, and changing its data, without communicating with other data. In this way, you can deal with a storage that doesn't support distributed transactions. Moreover, this approach can be used in the case of heterogeneous data storage, i. e. semi-transactions can start on one type of storage, and end on another. Such useful properties will be used below.
The logical question arises: how to implement semi-transitions in distributed systems avoiding getting bashed? To resolve this challenge you need to consider a lock-free approach.
Lock-Free
As is well known, lock-free approaches sometimes improve the performance of multithreaded systems, especially in the case of concurrent access to the shared resource. Nevertheless, it is completely unobvious that such an approach can be used in distributed systems. Let's dig in deeper and consider what is lock-free and why this property will be useful in solving our problem.
Some developers sometimes do not quite understand what lock-free is. The philistine view suggests that this is something related to atomic processor instructions. Here it is important to understand at the same time that lock-free means the use of atomic operations, while the converse is not true, i.e. not all atomic operations provide lock-free behavior.
An important property of the lock-free algorithm is that at least one thread makes progress in the system. But for some reason, this property is given as a definition very often (such a stupid definition can be found, for example, in Wikipedia). It is necessary to add one important nuance: progress is made even in case of delays of one or several threads. This is a very important moment, which is often overlooked, with serious consequences for the distributed system.
Why is the absence of a condition for the progress of at least one thread nullifies the concept of a lock-free algorithm? The fact is that in this case, the usual spinlock will also be lock-free. Indeed, the one who took the lock will make progress. There is a thread with progress ⇒ lock-free?
Obviously, lock-free means locks absence, while spinlock with its name indicates that this is a real lock. That is why it's important to add a condition about progress even in case of delays. After all, these delays can last indefinitely. The definition does not say anything about the upper time limit. And if so, then such delays will be equivalent in some sense to the thread termination. Thus lock-free algorithms produce progress in this case.
But who said that lock-free approaches are applicable only to multithreaded systems? Replacing the threads in the same process on the single node with the processes on different nodes, and the shared memory of the threads on the distributed storage, we get a lock-free distributed algorithm.
Node failure in such a system is equivalent to delaying the execution for a while because the recovery procedure requires some time to be completed. In this case, the lock-free approach allows you to continue working with other participants in the distributed system. Moreover, special lock-free algorithms can be run in parallel, detecting a concurrent change and eliminating the duplicates.
The exactly-once approach means having a consistent distributed storage. Such storages are typically a huge persistent key-value table with possible operations: set, get, and del. However, for a lock-free approach, a more complex operation is required: CAS or compare-and-swap. Let's consider this operation in more detail, the possibilities of its use, and also the outcome.
CAS
CAS or compare-and-swap is the primary and important synchronization primitive for lock-free and wait-free algorithms. The essence of it can be illustrated by the following Pseco:
CAS(var, expected, new): # everything inside the scope is performed atomically atomic: if var.get() != expected: return false var.set(new) return true
To optimize the implementation the common practice is returning not true or false but the previous value because very often such operations are performed in a loop. In order to get the expected value, it is necessary to read it before:
CAS_optimized(var, expected, new): # everything inside the scope is performed atomically atomic: current = var.get() if current == expected: var.set(new) return current # then CAS is expressed via CAS_optimized CAS(var, expected, new): return var.CAS_optimized(expected, new) == expected
This approach can save one reading. As part of our consideration, we will use a simple CAS form, since if you want, you can do this by yourself.
In the case of distributed systems, each change is versioned. So, first of all, we read the value from the consistent storage, getting the current version of the data. And then we try to write a new value, expecting that the version of the data has not changed. The version is incremented each time you update the data:
CAS_versioned(var, expected_version, new): atomic: if var.get_version() != expected_version: return false var.set(new, expected_version + 1) return true
This approach allows you to control the update more accurately, avoiding the ABA problem. In particular, versioning is supported by Etcd and Zookeeper.
We note an important property that provides the usage of CAS_versioned operations. The fact is that such an operation can be repeated without violation of the superior logic. In multithreaded programming, this property has no special value, because there if the operation was unsuccessful, then we know for sure that it did not apply. In the case of distributed systems, this invariant is violated, because the request can reach the recipient, but the successful answer is no longer there. Therefore, it is important to be able to forward requests without fear of violating high-level logic invariants.
This is exactly what the CAS_versioned operation provides. In fact, you can repeat this operation indefinitely until the real answer from the recipient returns. That, in turn, throws out a whole class of errors related to network interaction significantly simplifying the distributed system.
Example
Let's take a look at how to transfer money from one account to another based on CAS_versioned operation and semi-transactions, which belong, for example, to different instances of Etcd. Here I assume that the CAS_versioned function is already implemented appropriately based on the provided API.
withdraw(from, amount): # CAS-loop while true: # obtaining version and content version_from, amount_from = from.get_versioned() if amount_from < amount: return error.insufficient_funds if from.CAS_versioned(version_from, amount_from - amount): break return ok deposit(to, amount): # CAS-loop while true: version_to, amount_to = to.get_versioned() if to.CAS_versioned(version_to, amount_to + amount): break return ok transfer(from, to, amount): # 1st semi-transaction if withdraw(from, amount) is ok: # if the first semi-transaction succeeds # then perform the 2nd semi-transaction deposit(to, amount)
Here, we split our operation into semi-transactions, and perform each semi-transaction using the CAS_versioned operation. This approach allows you to work independently with each account, providing you with the possibility of using heterogeneous storages, not related to each other. The only problem that awaits us here is the loss of money in the case of the failure of the current process between the semi-transactions.
Queue
In order to go further, it is necessary to implement the queue. The idea is that for communicating handlers you need to have an ordered message queue avoiding data loss or duplication. Accordingly, all interaction in the chain of handlers will be built on top of this primitive. It is also a useful tool for analyzing and auditing incoming and outgoing data streams. In addition, mutations of the handler states can also be performed through the queue.
The queue consists of a pair of operations:
- Adding a message to the end of the queue.
- Extracting a message from the queue at a given index.
In this context, I do not consider deleting messages from the queue for several reasons:
- Several handlers can read from the same queue. Synchronization of the removal will be a non-trivial task, although it is not impossible.
- It is useful to keep the queue for a relatively long interval (day or week) for the possibility of debugging and auditing. The usefulness of such a property is difficult to overestimate.
- You can delete old items either by periodic schedule or by using the TTL on the queue elements. It is important to make sure that the handlers manage to process the data before the broom comes and cleans everything up. If the processing time is of the order of seconds, and TTL is of the order of days, then nothing like this should happen.
To store the elements and effectively implement the addition, we need:
- Value to store the current index. This index indicates the end of the queue.
- Elements of the queue, starting with the zero index.
Quasi Lock-Free Queue
To insert an item into a queue, we need to update two keys: the current index and the inserted element at the current index. Immediately there is an idea how to do it using the following sequence:
- First, increase the current index by one atomically using CAS.
- Then, write the inserted element at the index from the previous step.
However, this approach, oddly enough, has two fatal flaws:
- This implementation is not lock-free. It would seem that if we insert several elements in parallel, then at least one insertion is successful in this case. Lock-free? No! The fact is that we have 2 operations: inserting and reading. And although the insert itself is lock-free, however, inserting and reading is not! This is easily seen if we assume that immediately after the atomic update of the index a delay appears with the size of an eternity. Then we will never be able to read this and the subsequent elements and will be locked forever. This will pose a serious problem for the availability of our queue, because in case of a handler failure at this point, other handlers get stuck while reading the value from this position.
- Problems with the interaction of several queues. If the handler fails after updating the index, we do not know what index we need to use to write the value in if we continue working after the checkpoint. This index will be lost forever.
Thus, it is extremely important to keep lock-free with respect to all operations in order to preserve the high availability and fault tolerance of the system.
Lock-free Queue
Accordingly, arguing logically, there is only another variant of implementation: in the reverse order, i.e. we add an element to the end of the queue, and then update the index:
push(queue, value): index = queue.get_current_index() while true: # get a variable pointing to the queue item var = queue.at(index) # version = 0 corresponds to the new value, # means that the queue item must be empty at the time of writing if var.CAS_versioned(0, value): # CAS succeeds => update the index queue.update_index(index + 1) break # here is a tricky moment, see description below index = max(queue.get_current_index(), index + 1) update_index(queue, index): while true: # get the current versioned value cur_index, version = queue.get_current_index_versioned() # the current index may suddenly turn out to be larger # see description below if cur_index >= index: # someone proactively updated index to a more recent, # so the work is done break if queue.current_index_var().CAS_versioned(version, index): # index updated, the work is completed break # index has been updated by someone else, # but it is still outdated, try again
It is worth to clarify the tricky moment. The thing is that after the successful execution of the first semi-transaction, the handler may fail or be delayed (handler failure is, generally speaking, a special case of infinite delay). In this case, we want to preserve the lock-free property for our system. What will happen in this case?
The thing is that next push operation will spin in the loop endlessly because the current index is now unavailable for anyone to update! Therefore, it is now our task to update the index and we must proactively do this, independently looking for the next element of the queue.
After writing the value, you now need to update the current index. However, the pitfalls are also waiting for us: we can not just rewrite the value. The matter is that if the handler is delayed for some reason between the semi-transitions, then something else during this time interval could have time to add the element to the queue and update the current value of the index. So, a simple update of the index will not work, because we simply override the new index value. In addition, we need to update to the most recent value. What is the most recent value in this case? It will correspond to the highest value of the index, because the index corresponds to the position in the queue, and the higher the position, the more recent data we have written to the queue.
It is worth noting that we wrote the index just in order to be able to quickly find the end of the queue for further addition. So it is just an optimization. Without the index, this queue also works fine, just much more slowly, slowing linearly with the growth of the queue. Therefore, the lag of the index value does not lose the consistency, but only improves the performance of the queue operations.
Moreover, some storages provide a way to iterate through the records. Having organized a set of keys for access to the queue elements in a certain way, you can find the last element at once without going through the previous ones. This requires expanding the requirements for the storage, and therefore will not be considered. Here we only confine ourselves to the most common approach, which will work everywhere.
Interaction of Queues
In order to proceed, consider the following problem, that can be useful in the future.
Task. Transfer values from one queue to another.
This is the simplest task that can occur when processing data:
- There is no state, i.e. stateless handler.
- No transformations, the read value, and the written value are the same.
I think that it's not worth explaining that we want a fault-tolerant solution with the guarantee of concurrent exactly-once.
Without this requirement, processing would look like this:
handle(input, output): index = 0 while true: value = input.get(index) output.push(value) index += 1
Let's add just a little resilence. To do this, you need to load and save the state of the handler:
handle(input, output, state): # state is represented by the index index = state.get() while true: value = input.get(index) output.push(value) index += 1 # save the index in the state state.set(index)
This implementation is not exactly-once. The reason is that if the handler immediately crashes after adding an element to the output queue, but before saving the position, we get a duplicate.
To achieve an exactly-once guarantee, you need to store the index and write to the queue transactively. Since, generally speaking, queues and states can belong to different stores, between which there can be no distributed transactions, the only option that can be used is to break this transaction into semi-transactions:
# returns the smallest possible index to insert a new value get_next_index(queue): index = queue.get_index() # try to find an empty item while queue.has(index): # update the index similar to queue.push index = max(index + 1, queue.get_index()) return index # write the value at the specified index # returns true on success push_at(queue, value, index): var = queue.at(index) if var.CAS_versioned(0, value): # update the index queue.update_index(index + 1) return true return false handle(input, output, state): # load a state # intially {PREPARING, 0} fsm_state = state.get() while true: switch fsm_state: case {PREPARING, input_index}: # prepare for writing: save the index, # that will be used for writing output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) if output.push_at(value, output_index): # push succeeds, goto next item input_index += 1 # if the item was not empty push_at returns false, # and we need to retry using the same input_index fsm_state = {PREPARING, input_index} state.set(fsm_state)
What are the cases when push_at returns false? After all, at the previous step, we checked that the cell corresponding to the queue index is free. The fact is that generally speaking, different handlers can write to the output queue. And if so, during the finite state machine going to next step, this cell can already be written by another handler. In this case, we simply repeat the process with the same input_index. Such a conflict can occur only if any other handler succeeds, and so we obtain lock-free behavior.
In fact, we split the operation into two semi-transactions:
- Prepare for writing: save the output index to avoid the duplicates.
- Write the desired value using the saved index.
The smallest thing left is to add the concurrent property to exactly-once guarantee.
What's the problem with the code above? There are two of them:
- At the time of writing to the queue, it may turn out that another handler has already written exactly the same number, and therefore
push_atreturnsfalsein this case. And we will return to the previous step to push the same value twice. - The state can be updated from two different handlers, they will overwrite each other's data. This, in turn, can lead to very diverse race conditions.
Why is it important to support precisely concurrent exactly-once in this case? The fact is that a distributed system can not guarantee that at each time the number of equivalent handlers will be no more than one. This is due to the fact that it is impossible to guarantee the termination of the handler in case of the network split. Therefore, for any split of the transaction into its parts, it is necessary to assume concurrent processing.
The following code demonstrates the final solution of the task, taking into account the above issues:
# either write to an empty cell, or check that the value is already written # i.e. if the function returns true, # subsequent calls will also return true. # the same property holds for false push_at_idempotent(queue, value, index): return queue.push_at(value, index) or queue.get(index) == value handle(input, output, state): version, fsm_state = state.get_versioned() while true: switch fsm_state: case {PREPARING, input_index}: # prepare for writing: save the index, # that will be used for writing output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) # use idempotent function # thus the entire step becomes idempotent if output.push_at_idempotent(value, output_index): input_index += 1 fsm_state = {PREPARING, input_index} # try to atomically change the state if state.CAS_versioned(version, fsm_state): version += 1 else: # was a concurrent mutation, restore the state version, fsm_state = state.get_versioned()
The corresponding state diagram is represented here:

The basic idea is to make each action idempotent. This is necessary both for concurrency and for the correct continuation of execution after the failure and subsequent state recovery.
At the same time, no external and internal factors such as kernel panic, a sudden application crash, network timeouts, etc. are afraid of such an algorithm. You can always restart from the very beginning and continue as if nothing had happened. Hard termination will not lose any data and will not lead to duplicates and inconsistencies. You can also make application updates without stopping processing: we launch the new version together with the old one and then terminate the old one. Of course, new and old versions must be compatible with each other.
Thus, such a handler provides absolute stability related to failures, delays, and concurrent executions.
Solution of the Initial Task
Now we are ready to solve our initial task: the implementation of a stateful handler with the specific logic.
For this, we solve a slightly more general task: there is a user specific handler that has input queues and outputs the changed state and output values that will be pushed to the output queues:
# input parameters: # - input_queues - input queues # - output_queues - output queues # - state - the current state of the handler # - handler - user handler with the type: state, inputs -> state, outputs handle(input_queues, output_queues, state, handler): # get the current FSM state and its version version, fsm_state = state.get_versioned() while true: switch fsm_state: # input_indexes contains a list of current indexes of the input queues case {HANDLING, user_state, input_indexes}: # read values from each input queue inputs = [queue.get(index) for queue, index in zip(input_queues, input_indexes)] # calculate next indexes by increasing the current values next_indexes = next(inputs, input_indexes) # invoke user handler obtaining output values user_state, outputs = handler(user_state, inputs) # proceed to prepare for writing the results, # starting at zero position fsm_state = {PREPARING, user_state, next_indexes, outputs, 0} case {PREPARING, user_state, input_indexes, outputs, output_pos}: # get the index to write the value output_index = output_queues[output_pos].get_next_index() # switch to next step for writing fsm_state = { WRITING, user_state, input_indexes, outputs, output_pos, output_index } case { WRITING, user_state, input_indexes, outputs, output_pos, output_index }: value = outputs[output_pos] # write the value to the output queue if output_queues[output_pos].push_at_idempotent( value, output_index ): # goto next value on success output_pos += 1 # otherwise just goto PREPARING without position update # in case of increasing the output_pos # it's necessary to break the loop fsm_state = if output_pos == len(outputs): # all results have been written # goto handling phase {HANDLING, user_state, input_indexes} else: # go here if necessary to write next output value, # or to repeat the preparation step {PREPARING, user_state, input_indexes, outputs, output_pos} if state.CAS_versioned(version, fsm_state): version += 1 else: # was a concurrent mutation, restore the state version, fsm_state = state.get_versioned()
The state diagram looks like this:
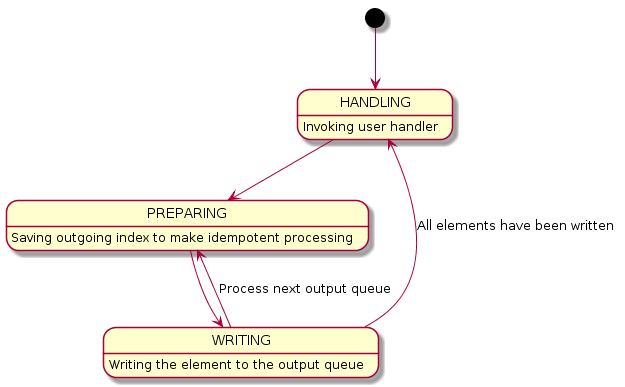
Here we have a new state: HANDLING. This state is necessary for committing the execution results of our handler, since, generally speaking, it can contain nondeterministic actions. Moreover, this is just our case. In addition to this, it can be seen that the PREPARING and WRITING phases are repeated several times until all the values have been written to the output queue. Once all the values are written, then the handler immediately goes to the HANDLING phase.
It's worth noting that here I did not handle situations related to the absence of values in the input queues, and also when the handler returns empty values for the output queues. This is done intentionally to avoid introducing unnecessary complexity for greater visibility of the resulting code. I think that the reader will be able to cope independently with such situations and process them correctly.
Also it worth noting another nuance. Recording to the database will occur through the output queue. This allows you to write a generalized code and divide the processing and writing into an external database.

Now we can write our handler containing specific logic solving our task:
my_handler(state, inputs): # add values from input streams state.queue.push(inputs) # update the window according to duration state.queue.trim_time_window(duration) # calculate the average avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary return state, [ avg, if need_update_counter: true else: # none means there is no need to add an element none ]
As you can see, the handler just does its job, while the complexity of manipulating queues and implementing a concurrent exactly-once guarantee is encapsulated inside the function handle.
Now you just need to add the interaction with the database:
handle_db(input_queue, db): while true: # at the very beginning, we create a transaction tx = db.begin_transaction() # read the current index inside the transaction. # the current index is stored in the database, # allowing updating state transactionally index = tx.get_current_index() # write the increased index tx.write_current_index(index + 1) # get the value from the input queue value = intput_queue.get(index) if value: # increase the counter tx.increment_counter() tx.commit() # either the transaction is successful, # and the counter is updated together with the index, # or the transaction is aborted and we just repeat it again
There are no surprises. Because all state is updated within the single transaction then this handler can be run in parallel with itself, and, therefore, it provides a guarantee of concurrent exactly-once by definition. This implementation immediately demonstrates the usefulness of transactions.
Out of the Scope
The above algorithm is only the first step on the way to efficient and transactional data processing. Below I will give a list of possible optimizations and improvements that are useful in some cases, with minimal comments and considerations.
Storage Optimizations
Consistent storages typically support richer functionality, such as transactional behavior on a limited key set, batching atomic actions, and range scanning. I have considered only the most general storage with the simplest primitive and showed that even in this case it is possible to build a transactional scalable system.
Asynchronous Publishing
After processing the input streams, the stage of publishing the results to the output queues follows. This publication is performed sequentially, each subsequent record is waiting for the previous one. Because the data itself is already saved and ready for pushing, then the idea arises to parallelize it. In this way, it is possible to shoot with unimaginable ease both your legs and both hands. So I leave it as a homework.
Batching
An obvious optimization for increasing the throughput of queues is the batching of messages. Indeed, in the queue, it is possible to push not the values themselves, but references to groups of values. The values themselves can be prepared little by little, with the possibility of storing them on separate shards, storages or even files. In this case, the pointer to the element of the queue will become a composite pointer. In addition to the index in the queue, it should also contain a position in the batch.
Double Sharding
To parallelize processing, sharding is often used. However, if there are a large number of handlers, then they all start writing to the same queue. To avoid unnecessary contention here, you can shard queue once again, but for writing, in addition to sharding the reads.
Fundamentality
Let us discuss the basis for applying this approach. It is clear that one can not break any transaction into a set of atomic operations. The reason is trivial: if this could be done for any situation, then it would always be so. Therefore, it is important to outline the class of problems that can be solved using this approach.
If we carefully look at the actions that we are taking, we can see a number of characteristic features:
- Transactions are split into semi-transactions, which are executed sequentially. The total effect of all semi-transactions is exactly the same as the effect of the entire transaction.
- Isolation is not an important requirement. The client can observe the intermediate actions of the transaction as if the transaction actions were visible to everyone.
- The first and only the first semi-transaction can verify the validity of the subsequent actions. If the validation fails, then we simply do not start the follow-up actions. However, if we started the transaction by applying the first semi-transaction, then we do not have the possibility to terminate the execution. So the subsequent semi-transactions only applies the subsequent actions moving the execution forward. This is due to the simple fact: any mutation is visible to the client.
The latter property can be slightly weakened, however, firstly, this is not always possible, and secondly, it can greatly complicate the code.
Let's look at the examples, why separation on a semi-transactions is possible:
transfer(from, to, amount): # 1st semi-transaction if withdraw(from, amount) is ok: # if the first semi-transaction succeeds # then perform the 2nd semi-transaction deposit(to, amount)
Here, withdraw checks may not pass, at the same time deposit will never do it: who refuses extra money? However, if the function deposit for some reason can return a failure (for example, the account was blocked, or there is a limit on the top on the number of funds), then there are problems. It would seem that they can be solved by transferring funds back, but who said that at that moment the original account was not blocked? You can easily get results when the transaction hangs, and the funds will need to be redirected somewhere else, but already in manual mode.
Processing data in real time, in my opinion, is a reference example, when such an approach works perfectly. Indeed, at the very beginning, we check to see if there is any data that needs to be processed. If they are not, then we do not start anything. If there is data, then we run the handler, save the result, and then write it to the output queues sequentially. Because queues are unlimited, then the writing to them always ends in success, and hence transactional behavior will sooner or later be completed. At the same time, one can see an intermediate state, but this will not cause any dissatisfaction: it is an oxymoron to fix the inconsistency between shards where there are no distributed transactions.
Two-Phase Lock-Free Commit
Since we are discussing the transactional behavior, it would be a good idea to expose a two-phase commit.
Usually it consists of two phases: first, we lock the records and check the possibility of executing the commit, and further, if the previous phase passed successfully, then apply the changes simultaneously unlocking the records. In this sense, transactions based on a two-phase commit can implement an optimistic-pessimistic blocking scheme:
- Optimism. From the client's point of view, during the execution of the transaction, we do not lock the records but only save, for example, the versions or timestamps, for subsequent validation on the commit.
- Pessimism. During the distributed transaction commit, we begin to lock the records.
Some additional details can be read, for example, here.
Of course, this is a somewhat voluntaristic explanation of the concepts of optimism and pessimism; they can only be applied to the transaction itself, but not to its individual parts, such as a commit. However, the commit phase can be viewed as a separate transaction, returning these concepts to their original meaning.
A pessimistic scheme of two-phase commit hints at a simple fact: this action is not lock-free by definition, which can significantly reduce the processing speed in case of random delays or failures. And even more so, the transaction can not be executed concurrently, because they will only interfere with each other providing conflicts instead of boost.
In the case of semi-transactions based on CAS operations, you can also see a number of similar features. Recall how the transactional write occurs to a queue:
# here is only the fragments of code that we are interested in handle(input, output, state): # ... while true: switch fsm_state: case {HANDLING, ...}: # handle the data and save the result fsm_state = {PREPARING, ...} case {PREPARING, input_index}: # prepare for writing... output_index = ...get_next_index() fsm_state = {WRITING, output_index, ...} case {WRITING, output_index, ...}: # actual write that uses output_index
In fact, here we have the following. After processing the data, we want to commit the result to the output queues. The commit process takes place in two phases:
- PREPARING. Obtain an index that will be used to write the result.
- WRITING. Store the result at the obtained index. On conflict, the transaction will be repeated starting from the PREPARING phase.
This is very similar to what happens during a two-phase commit. Indeed, during the first phase we prepare the necessary data for writing, and during the second phase, we do write. However, there are fundamental differences:
- Obtaining an index during the first phase does not lock the output queue. Moreover, this phase is non-intrusive, because generally does not change the state of the queue, all actions occur in the second phase.
- In the classical two-phase commit after the successful first phase, the second application is unconditionally applied, i.e. the second phase does not have the possibility to fail. However, in our case, the second phase may not be successful, and the action must be repeated again.
Thus, in the lock-free version of the two-phase commit, the first action does not lock the state, which means it allows to perform the transaction action completely optimistically, increasing the availability of data for the change.
Consistency Requirements
Let's discuss the required consistency levels of the storage. An interesting point is that the safety requirement of the algorithm is not violated in the case of Stale Reads. The most important thing is to correctly write data through the CAS operation: between reading the value and writing during its execution there should be no intermediate changes. This leads us to the following possible consistency levels and storages:
- Distributed single register: storages based on atomic register change (for example, Etcd and Zookeeper):
- Linearizability
- Sequential consistency
- Transactional: storages with transactional behavior (for example, MySQL, PostgreSQL, etc.):
- Serializability
- Snapshot Isolation
- Repeatable Read
- Read Committed
- Distributed Transactional: NewSQL storage:
- Strict Consistency
- Any of the above
However, the question arises: how the consistency affects the system? The answer is simple: only performance will be affected. If we read stale data then during the CAS operation we immediately obtain the conflict and all the data will have to be thrown out. Therefore, it makes sense to consider stricter consistent levels, for example, at least Read My Writes.
Conclusion
Transactional behavior during data processing allows you to achieve exactly-once guarantees. However, this solution is not scalable, because transactional processing is based on a two-phase commit, which locks the corresponding records. Adding the requirement of concurrent execution to avoid pauses as well as the requirements of heterogeneity sets the next hitherto unattainable level because distributed transactions lead to conflicts in case of high concurrency dramatically reducing the processing throughput.
Separation of transactions into semi-transactions and the use of a lock-free approach can significantly improve scalability and heterogeneity.
The important advantages of the approach are:
- Heterogeneity: a single abstraction for different types of storages.
- Atomicity: each action is an atomic mutation of the persistent state.
- Safety: the approach implements the strictest guarantee of real-time processing: exactly-once.
- Concurrent: concurrent execution completely eliminates the processing delays.
- Real-time: real-time data processing.
- Lock-free: at any stage, data is not locked, there is always progress in the system.
- Deadlock free: the system will never come to a state from which it can not make progress.
- Race condition free: the system does not contain race conditions.
- Hot-hot: there are no delays to restore the system from failures.
- Hard stop: you can hard-stop the system at any time without implications.
- No failover: the algorithm loads the current state and immediately makes the progress in the system without having to restore the correctness of the previous state.
- No downtime: updates occur without downtime.
- Absolute stability: resilience to failures, delays and concurrent execution.
- Scalablility: sharding the queues and corresponding handlers allows you to scale the system horizontally.
- Flexibility: allows you to flexibly configure the pipeline and the corresponding system parameters.
- Fundamental: semi-transactions solve a wide class of problems.
It is worth noting that there is an even more fundamental and performant approach. But it is another story.

Newly Introduced Concepts
It is useless to try finding the information related to the following terms:
- Concurrent exactly-once.
- Semi-transactions.
- Lock-free two-phase commit, optimistic two-phase, or two-phase commit without locks.
Challenges
- Implement asynchronous writes to the output queues.
- Implement reliable lock-free funds transfer based on semi-transactions and queues.
- Find a stupid mistake in the handler.
References
[1] Wikipedia: ABA problem.
[2] Blog: You Cannot Have Exactly-Once Delivery.
[3] Blog: Attainability of the Lower Bound of the Processing Time of Highly Available Distributed Transactions.
[4] Blog: Replicated Object. Part 3: Subjector Model.
[5] Wikipedia: Non-blocking algorithm.
Excellent read, very accessible and thorough at the same time, thank you. We are already looking forward to your next post :)
ReplyDeleteBeautifully presented write up on such a complex and little understood topic.
ReplyDelete